There are several scenarios to use Unicode characters in Power BI including but not limited to:
- Creating simple KPI columns in Table or Matrix visuals
- To show the status of a measure more visually like using starts
- Using Unicode characters as icons in your reports representing the subject
Chris Webb explained some of the above scenarios here.
In this post I explain how you can use Power BI as a tool to generate almost all valid Unicode characters in Power BI. You can download the PBIT at the bottom of this post. Then you can copy the Unicode characters from Power BI and use them in all textual parts of your report like visual titles, text boxes and so on.
The Unicode planes start from 0 to 1,114,111 which is decimal equivalent of 0 to 10FFFF in hexadecimal numeral system. For more information on Unicode planes check this out.
So, a simple way to generate all possible Unicode characters is to generate a list of decimal numbers starting from 0 ending at 1,114,111. This way we generate a series of decimal numbers regardless of the gaps between starting and ending Unicode blocks. Then using UNICHAR() function in DAX to generate corresponding Unicode characters. With the following DAX expression you can easily generate a list and the corresponding Unicode characters:
Generate Unicode =
SELECTCOLUMNS(
ADDCOLUMNS(
GENERATESERIES(0, 1114111, 1)
, "Unicode Character"
, IFERROR(UNICHAR([Value]), "Not Supported")
)
, "Decimal Value", [Value]
, "Unicode Character", [Unicode Character]
)
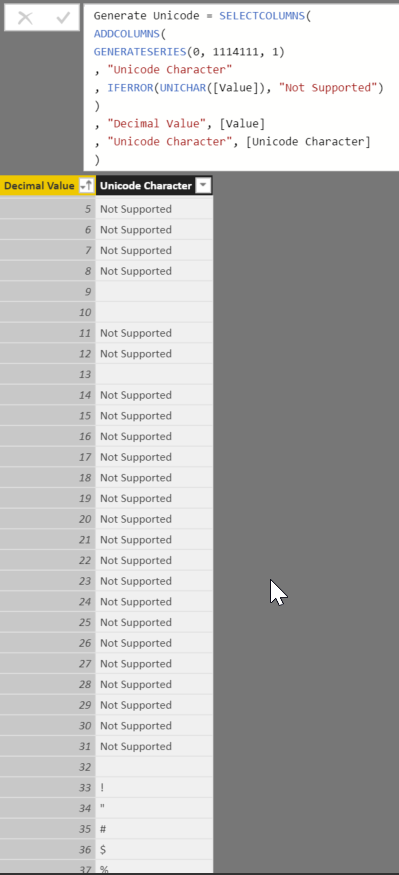
While generating Unicode characters with the above scenario is technically working, but, it is not good enough. With than 1 million rows, including all decimal numbers even those ones that are not valid, finding a Unicode character looks to be very hard.
So I thought of a better way of getting data from web that comes with Unicode Planes, Unicode Blocks and block range. One of the best online sources I found is Wikipedia.
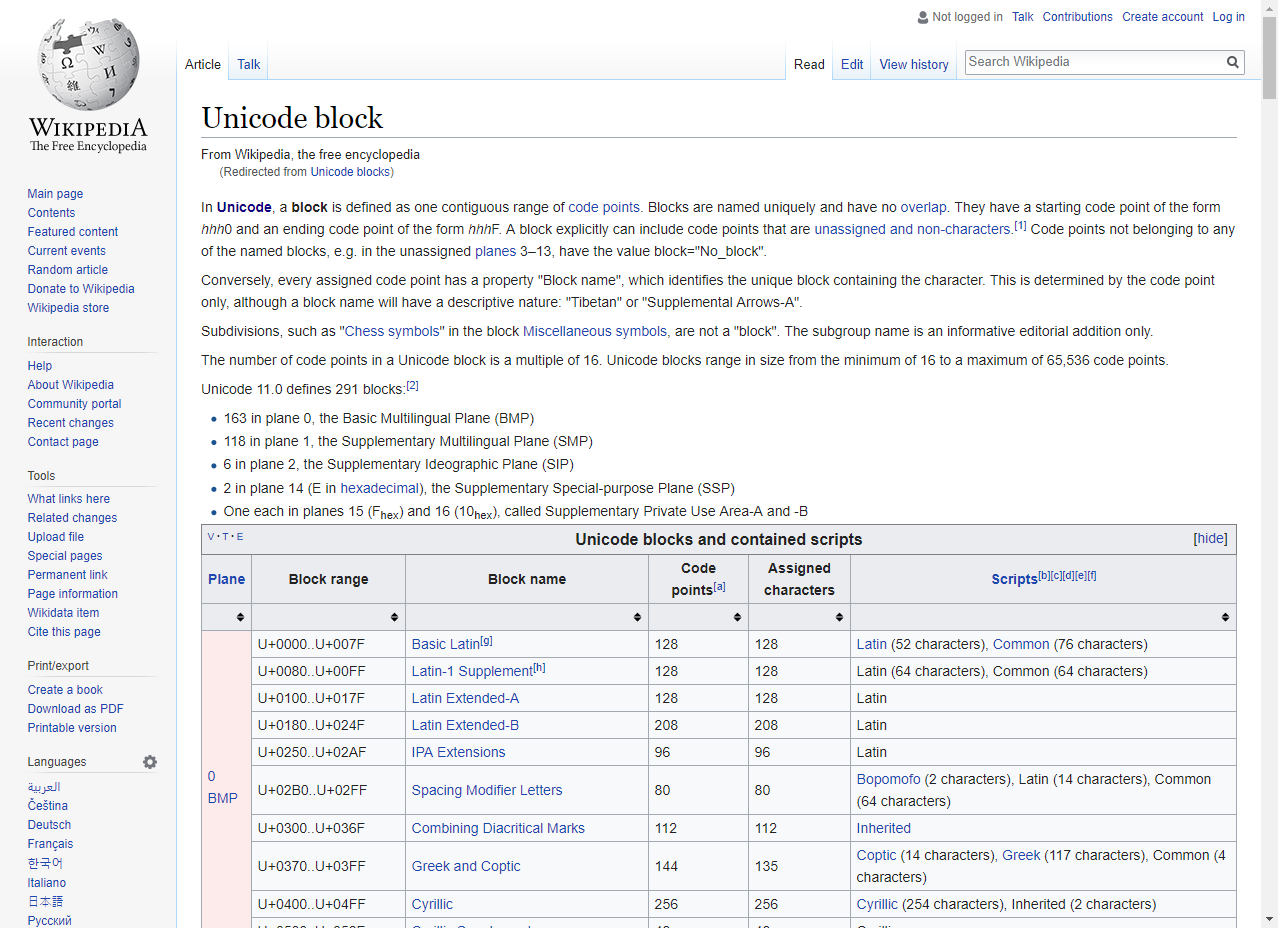
So we just need to:
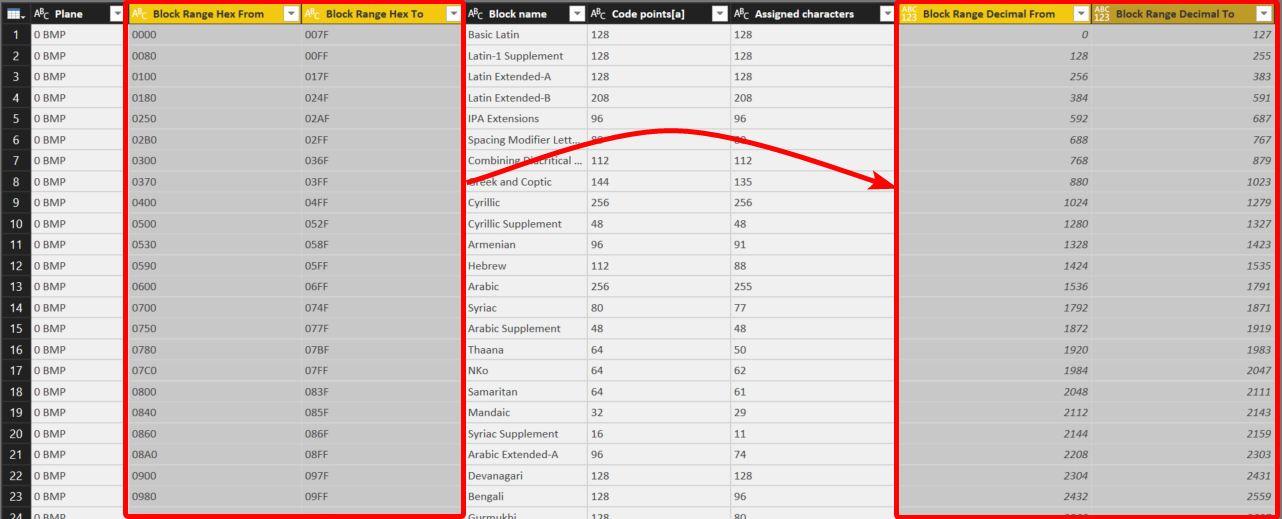
- import data from the table in the above Wikipedia link
- split the “Block Range” column to two columns containing Block Range Start and Block Range End
- generate values between Block Range Start and Block Range End

The only part which is not that straight forward is converting hexadecimal values to decimal values. Remember, UNICHAR() function only accepts decimal input values.
I started building a Power Query function to convert hexadecimal to decimal, but, it was buggy and not efficient at all. So I googled hex to decimal and found this article written by “Greg Deckler” that works very well, much better than what I was building.
UPDATE: A big shout out to Rocco Lupoi who shared his Power Query code in the comments. His code is NOT recursive, so it performs better on larger amounts of data. Give Rocco’s code a go and see how it works in your scenario.
Now that I have the start and end Unicode Block Ranges in decimal, I can easily generate a list of values between the start and end ranges in Power Query using “List.Generate”.

Expanding the “Unicode Decimal” list column gives us all decimal values in range that can be passed to UNICHAR() function in DAX.

After loading the data we just need to add a calculated column with the following expression:
Unicode Character = IFERROR(UNICHAR('Unicode'[Unicode Decimal]), "Not Supported")

Now you can easily find and copy a Unicode Character and use it in your report pages, visuals and so on without consuming a lot of storage. As you may already know, after September 2018 release of Power BI Desktop we can easily copy values from Table and Matrix visuals which makes it easy to copy Unicode Values.
The PBIT file is available to download, all you need to do is to open the file, right-click on any desired Unicode Character from the Unicodes Table then click “Copy value”.
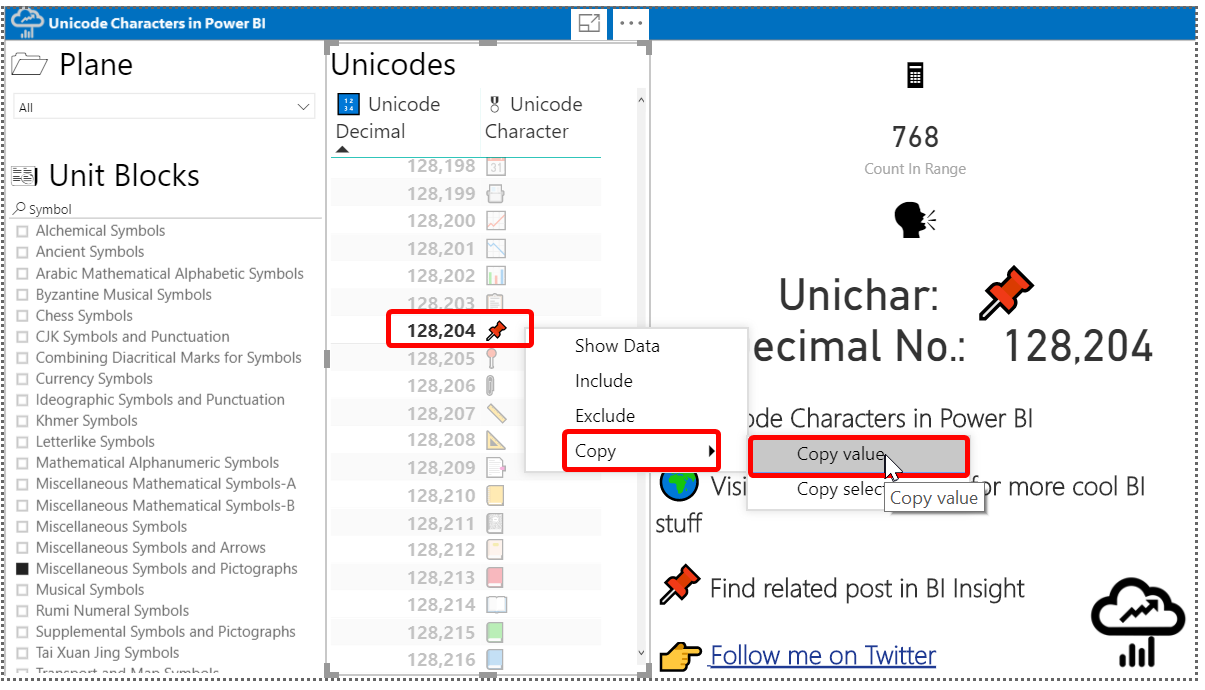
You can now paste the character in all textual parts of a report in Power BI including in the visual titles and Text boxes. You can even use the Unicode characters to rename a measure or column in the “Fields” tab from “Visualization” pain.

Download the PBIT file from here.
More to read: Unicode Consortium official website.
Discover more from BI Insight
Subscribe to get the latest posts sent to your email.
Soheil
The link to the PBIX is not working
Thanks,
Ed Dror
Great tutorial, thank you very much.
Great post, thanks. There does not appear to be a file to download when I click through to dowload page.
Hi Matt,
Happy new year and thanks for raising the download issue.
I fixed the problem so you should be able to download the file now.
the link to download is not working… =(
Hi Leonel,
Welcome to BIInsight.com.
The link should work now.
Cheers.
I would like to propose a non recursive function which transform an hexadecimal (or any other base not greater than 16) value to a correspondent decimal .
As plus 🙂 the function accept also lower case hexa-digits.
Here the code:
let
fnHex2Dec = (input, base) =>
let
values = [
0=0,
1=1,
2=2,
3=3,
4=4,
5=5,
6=6,
7=7,
8=8,
9=9,
A=10,
B=11,
C=12,
D=13,
E=14,
F=15
],
digits=Text.ToList(Text.Upper (input)),
dim=List.Count(digits)-1,
exp=if base=null then 16 else base,
Result = List.Sum(List.Transform({0..dim}, each Record.Field(values,digits{_})*Number.Power(exp,dim – _)))
in
Result
in
fnHex2Dec
Hi Rocco,
Welcome to BIInsight.com.
Thanks for sharing the code mate, it works beautifully.
Cheers.
hi
I have a table that has a column called Debtor. The values of this column are written in Persian numbers and text type. How can I convert these values to standard English numbers?
Hi Fatemeh,
Welcome to biinsight.com.
This is an excellent question indeed.
To answer your question, I had to go through a kind of long process such as doing some initial research to see if anyone else answered a similar question, installing Persian language on my laptop, finding some sample data in Persian etc…
Long story short, while Power BI detects Persian numbers as text, my initial thought is to transform the Persian numbers to their equivalent English numbers using a custom function in Power Query.
You may require to create another custom function to reverse the process if you like to show the results in Persian when visualising the data.
BTW… here is the function I wrote to transform Persian numbers to English numbers. It can transform decimal values and remove the thousand separators (if any).
Here is the code:
letfn_PersianToEnglishNumber =
/************************Function body************************/
(Persian_Number as text) as number =>
let
#"Base Table" = Record.ToTable(Record.FromList(List.Combine({{"?".."?"}, {"?", "/"}, {Character.FromNumber(1644)}}), {"0".."9", "", ".", " "})),
#"Input to Table" = Table.FromList(Text.ToList(Persian_Number), null, {"PersianValue"}),
#"Index Column Added" = Table.AddIndexColumn(#"Input to Table", "Index", 1, 1, Int64.Type),
#"Joining Input Table and Base Table" = Table.NestedJoin(#"Index Column Added", "PersianValue", #"Base Table", "Value", "Mapping", JoinKind.Inner),
#"Sorted Rows" = Table.Sort(#"Joining Input Table and Base Table",{{"Index", Order.Ascending}}),
#"English Number" = Number.FromText(Text.Replace(Text.Combine(Table.ExpandTableColumn(#"Sorted Rows", "Mapping", {"Name"}, {"Name"})[Name]), " ",""))
in
#"English Number"
/************************Function documentation************************/
, FunctionType = type function
(
Persian_Number as
(type text meta
[
Documentation.FieldCaption = "Persian Number ??? ?????",
Documentation.FieldDescription = "Accepting persian numbers as text. ??? ?????? ?? ??? ????? ?? ?? ???? ???? ???????",
Documentation.SampleValues = {"???/..."}
]
)
) as number
meta
[
Documentation.Name = "fn_PersianToEnglishNumber",
Documentation.Description = "Converts persian numbers to english numbers.??? ?????? ????? ????? ?? ?? ????? ??????? ???? ????? ????? "
]
in
Value.ReplaceType(fn_PersianToEnglishNumber, FunctionType)
I reckon my website messes up with the quotation marks, so you can download the above code from my GitHub.
You have to invoke the fn_PersianToEnglishNumber function to transform all Persian numbers.
I am sure there must be better ways to overcome this challenge but that’s what I came up with.
Hopefully that helps.
Cheers