
I explained what SCD means in a Business Intelligence solution in my previous post. We also discussed that while we do not expect to handle SCD2 in a Power BI implementation, we can handle scenarios similar to SCD1. In this post, I explain how to do so.
Scenario #
We have a retail company selling products. The company releases the list of products in Excel format, including list price and dealer price, every year. The product list is released on the first day of July when the financial year starts. We have to implement a Power BI solution that keeps the latest product data to analyse the sales transactions. The following image shows the Product list for 2013:
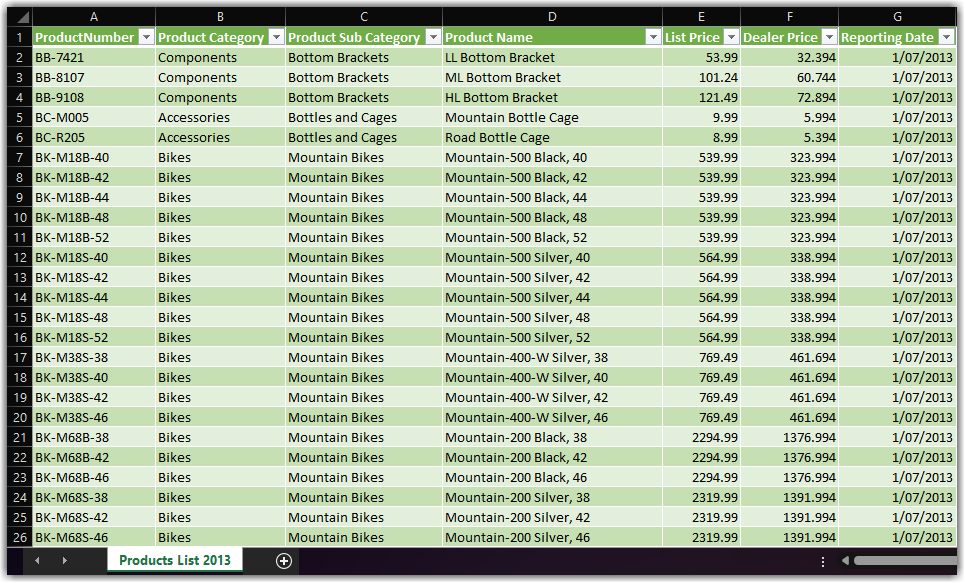
So each year, we receive a similar Excel file to the above image. The files are stored on a SharePoint Online site.
Scenario Explained #
As the previous post explains, an SCD1 always keeps the current data by updating the old data with the new data. So an ETL process reads the data from the source, identifies the existing data in the destination table, inserts the new rows to the destination, updates the existing rows, and deletes the removed rows.
Here is why our scenario is similar to SCD1, with one exception:
- We do not actually update the data in the Excel files and do not create an ETL process to read the data from the Excel files, identify the changes and apply the changes to an intermediary Excel file
- We must read the data from the source Excel files, keep the latest data while filtering out the old ones and load the data into the data model.
As you see, while we are taking a very different implementation approach, the results are very similar with an exception: we do not delete any rows.
Implementation #
Here is what we should do to achieve the goal:
- We get the data in Power Query Editor using the SharePoint Folder connector
- We combite the files
- We use the ProductNumber column to identify the duplicated products
- We use the Reporting Date column to identify the latest dates
- We only keep the latest rows
Getting Data from SharePoint Online Folder #
As we get the data from multiple files stored on SharePoint Online, we have to use the SharePoint Folder connector. Follow these steps:
- Login to SharePoint Online and navigate to the site holding the Product list Excel files and copy the site URL from the browser
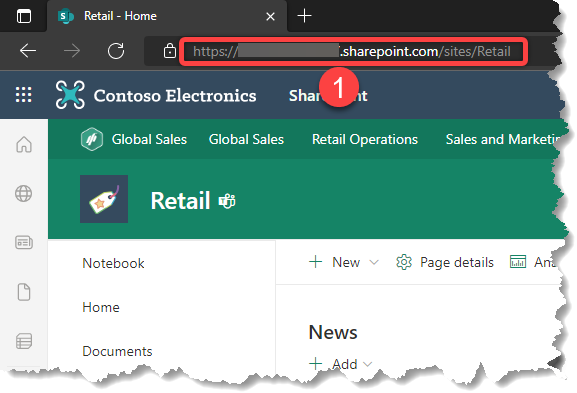
- From the Get Data in the Power BI Desktop, select the SharePoint Folder connector
- Click Connect

- Paste the Site URL copied on step 1
- Click OK
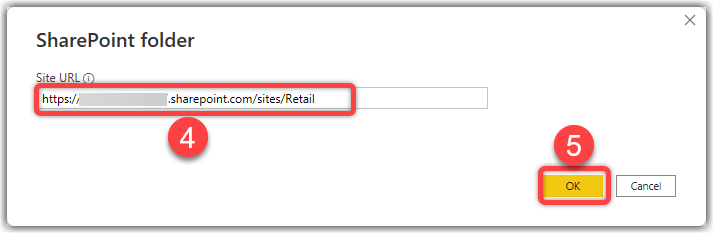
- Click Transform Data
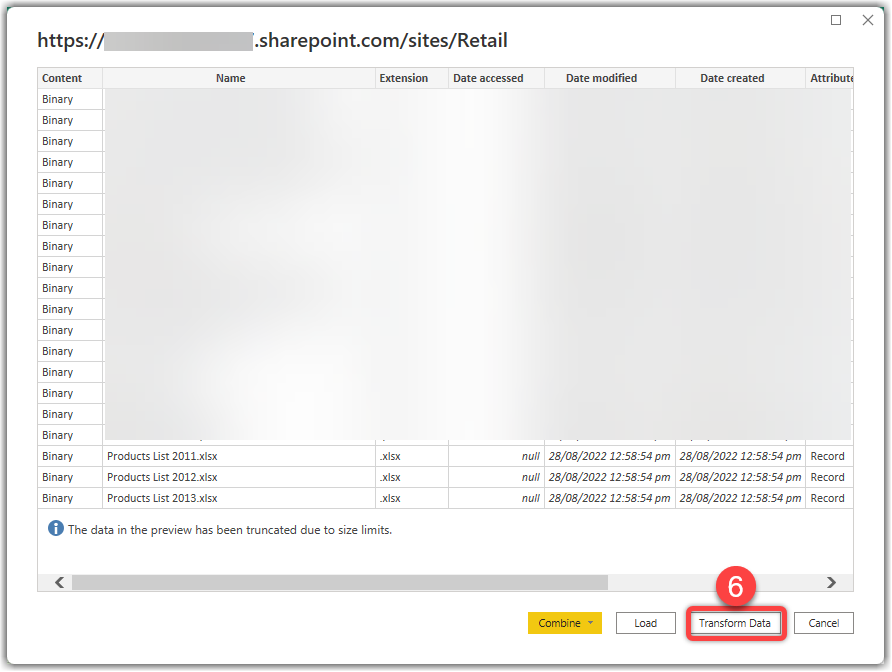
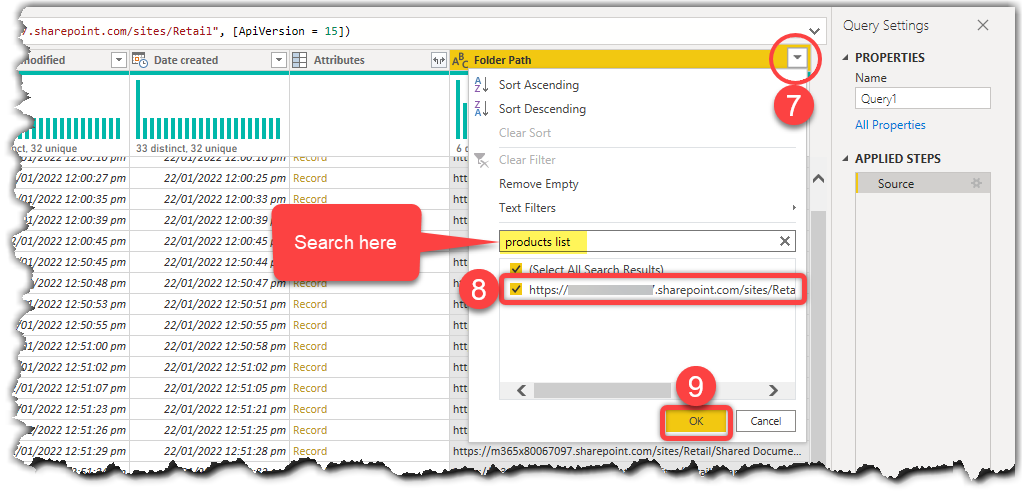
- Click the filter dropdown on the Folder Path column
- Find the Products List folder hosting the Excel files and select it
- Click OK
- Rename the query to Product
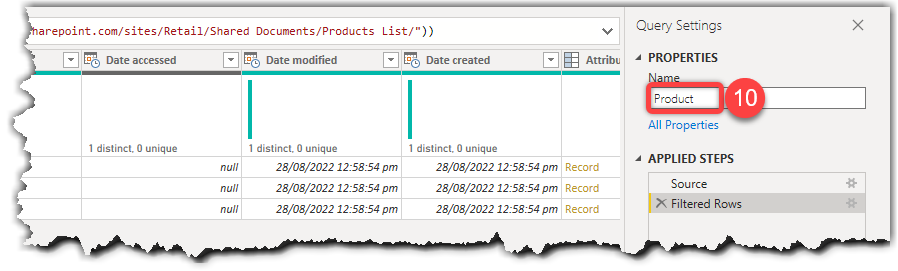
So far, we are connected to the SharePoint Online Folder in Power Query Editor. The next step is to combine the Excel files.
Combining Files #
We have multiple options to combine binary files in a table from the Power Query Editor. In this post, we use the most straightforward method:
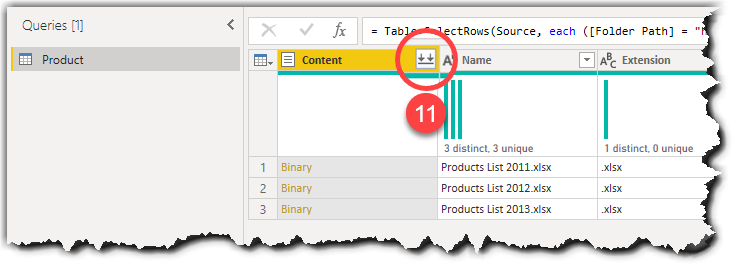
- Click the Combine Files button from the Content column
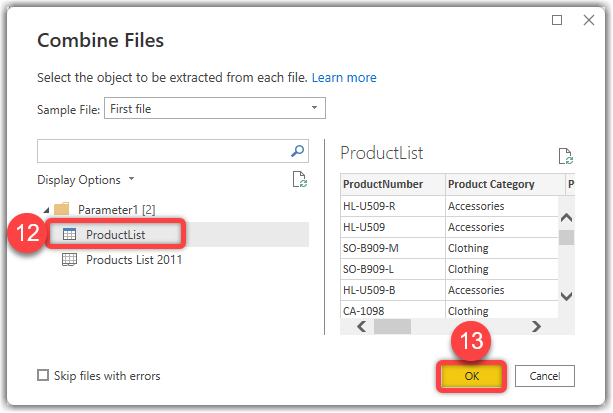
- Select the ProductList table
- Click OK
The above process creates a couple of queries grouped in separate folders, as shown in the following image:
So far, we have successfully combined the Excel files. The next step is to keep the latest data only.
Keeping the Latest Data #
In the next few steps, we look closer at the data, and we implement a mechanism to identify the latest data, keep them and load them into the data model.
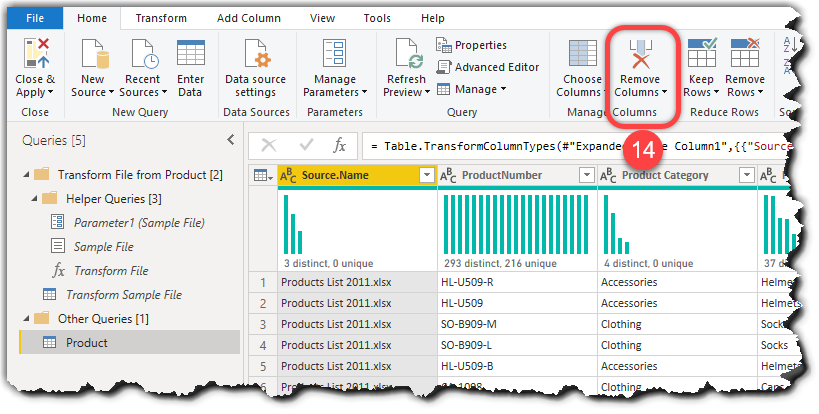
- Looking at the results of the combined data shows a Source.Name column that we do now require to keep, so we remove it by selecting it and clicking the Remove Columns button from the Home tab
So far, we have connected to the SharePoint Online Folder and combined the contained Excel files. Let’s look at the data and see what we’ve got. I sorted the data by ProductNumber to better understand the data changes. The following image shows the results:
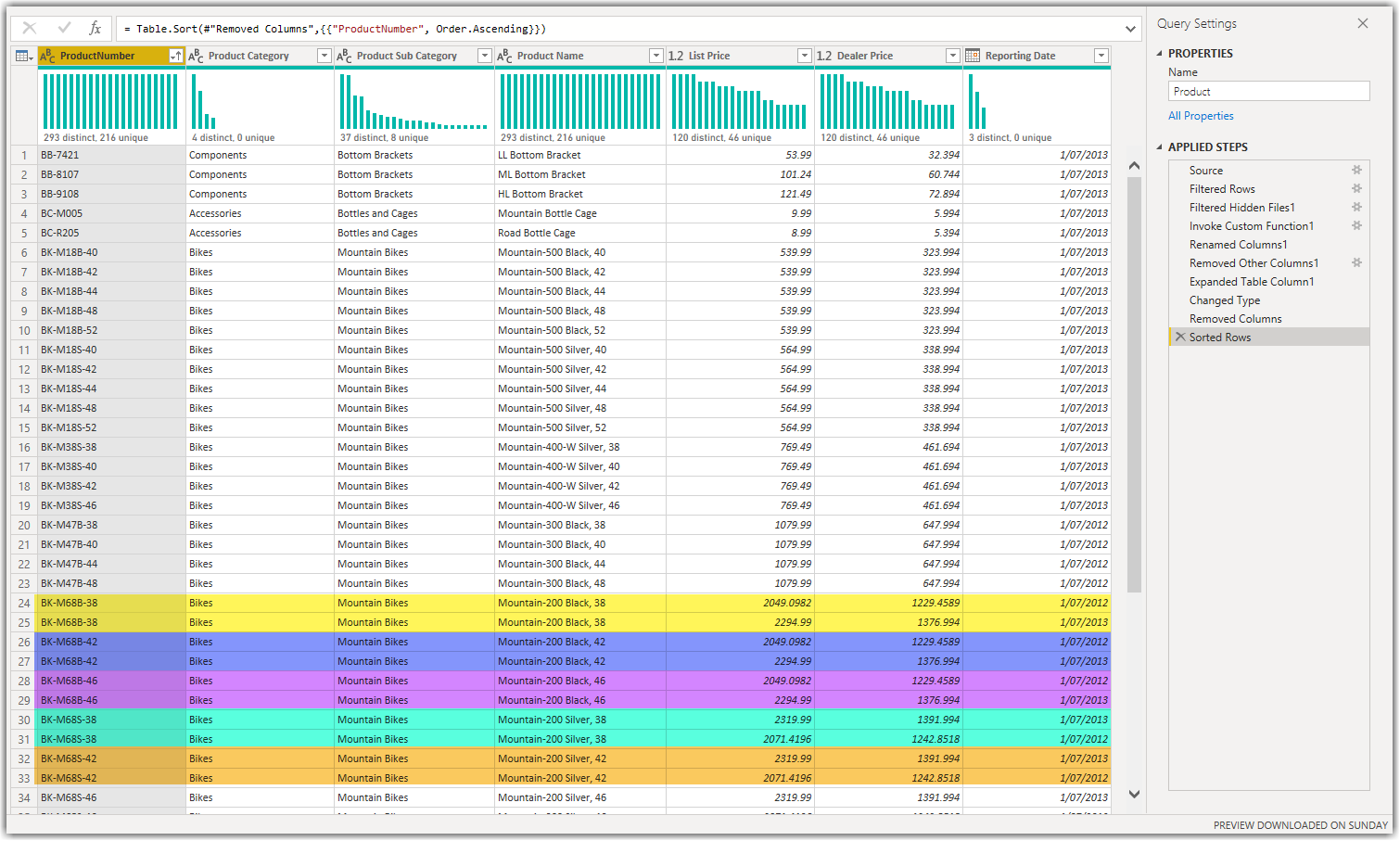
As the above image shows, there are multiple products appearing in multiple lists. That is exactly what we expected to see. The goal is to keep the latest product data only based on the Reporting Date. So we should get the ProductNumber and the maximum of the Reporting Date. To achieve this, we use the Group By functionality in Power Query Editor. Using the Group By from the UI in the Power Query Editor uses the Table.Group() function in Power Query. As the Group By process does not need the data to be sorted we remove the Sorted Rows step. With that, let’s get the job done.
- Select the ProductNumber column
- Click the Group By column from the Transform tab
- Enter Reporting Date for the New column name
- Select Max from the Operation dropdown
- Select the Reporting Date from the Column dropdown
- Click OK
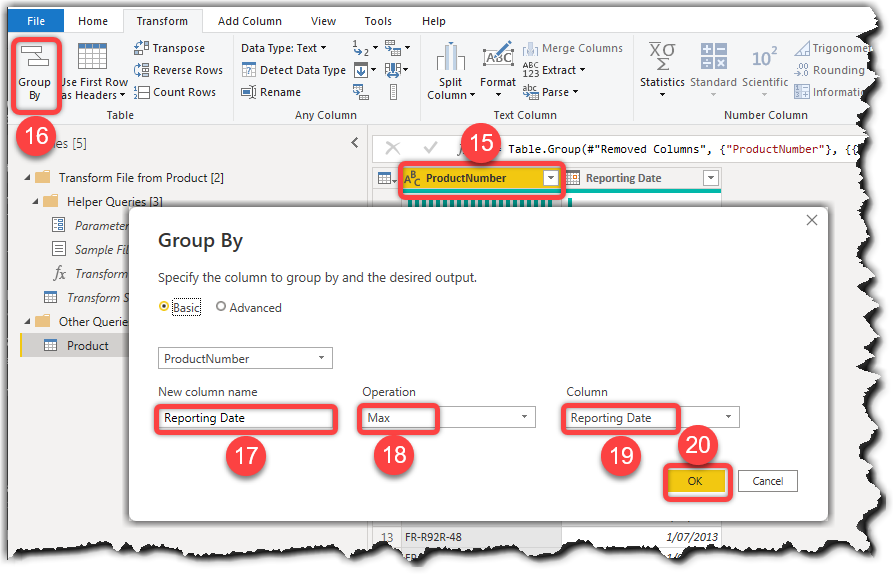
The following image shows the results:
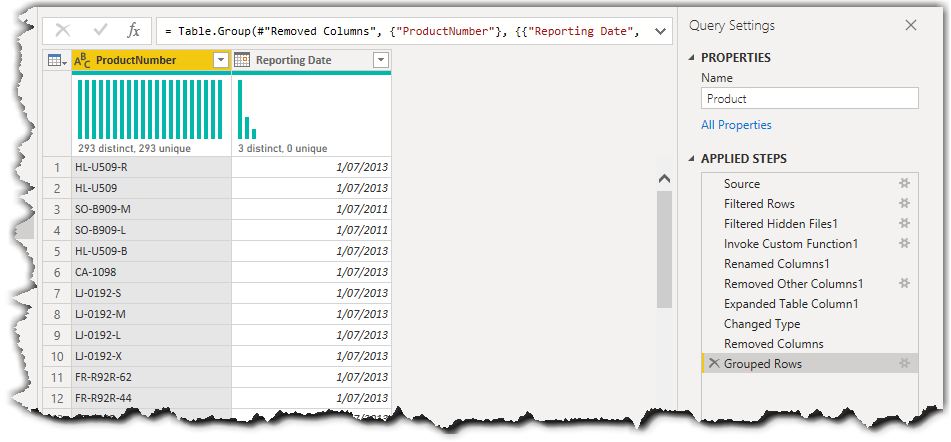
We now have all product numbers with their latest reporting dates. The only remaining piece of the puzzle is to join the results of the Grouped Rows step with the data of its previous step. For that we use the Merge Queries functionality which runs the Table.NestedJoin() function in Power Query.
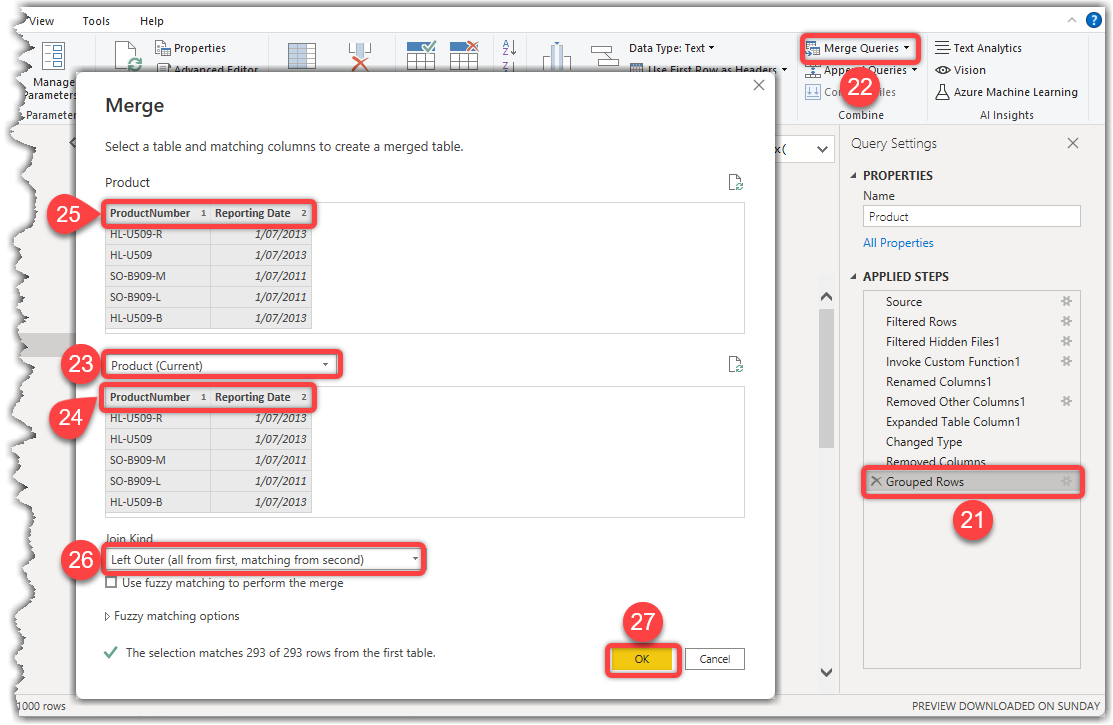
- Select the Grouped Rows step from the Applied Steps list from the Query Settings pane
- Click the Merge Queries button from the Home tab
- Select the Product (Current) table from the dropdown. Note that we are selecting the current query (Product)
- On the top table, press the Ctrl button on your keyboard and select the ProductNumber and the Reporting Date columns sequentially
- Do the same for the bottom table. Note that the sequence of selecting the columns is important
- Ensure that the Join Kind is Left Outer (all from first, matching from second)
- Click OK
As mentioned earlier, the merge operation uses the Table.NestedJoin() function, which accepts two tables (highlighted in yellow in the expression below), a list of their key columns to use on the join (highlighted in red in the expression below), a name for the new column of type table and the join kind. In the above operation, as the Grouped Rows is the last transformation step, we joined the results of the Grouped Rows transformation step by itself. Here is the code generated by Power Query Editor after going through the step 21 to 27:
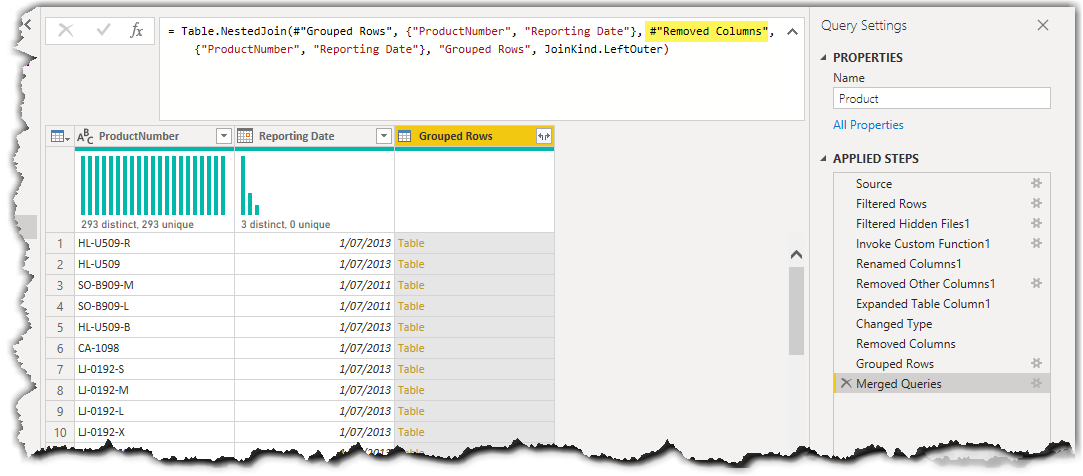
Table.NestedJoin(#"Grouped Rows", {"ProductNumber", "Reporting Date"}, #"Grouped Rows", {"ProductNumber", "Reporting Date"}, "Grouped Rows", JoinKind.LeftOuter)But that is not what we want, we do not need to join the results of the Grouped Rows transformation step by itself. We need to join the results of the Grouped Rows transformation step by the results of the Removed Columns step. Therefore, we have to modify the above expression as follows:
Table.NestedJoin(#"Grouped Rows", {"ProductNumber", "Reporting Date"}, #"Removed Columns", {"ProductNumber", "Reporting Date"}, "Grouped Rows", JoinKind.LeftOuter)The following image shows the modification made in the expression and the results:
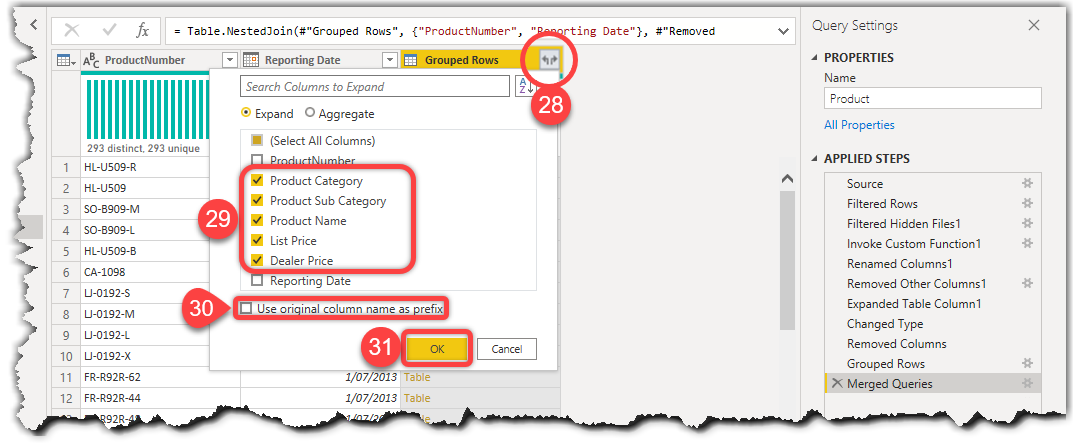
- Click the Expand button on the Grouped Rows column
- Deselect the ProductNumber and Reporting Date columns to keep the other columns selected
- Untick the Use original column name as prefix option
- Click OK
All done! The following image shows the final results:
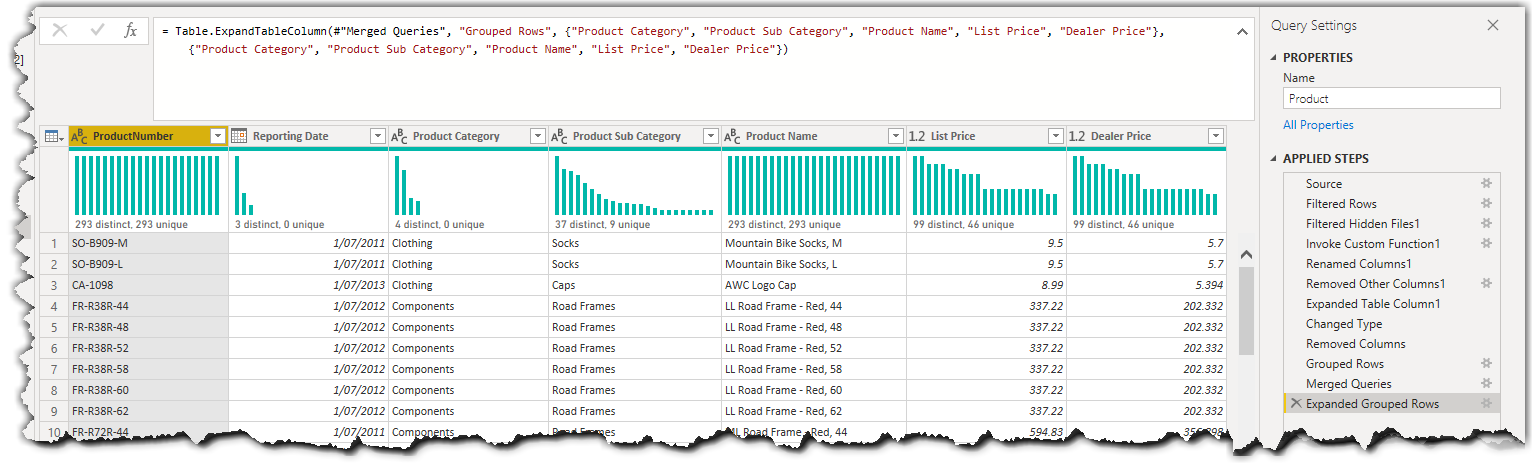
We can now apply the changes to load the data into the data model. With this technique, when a new Excel file (a new Product List) lands in SharePoint Online, Power BI goes through the above transformation steps to ensure we always have the latest Product data loaded into the data model, which is very similar to the behaviour of an SCD1.
Have you used this method before? Do you have a better technique to handle a similar scenario? You can share your thoughts in the comments section below.
Discover more from BI Insight
Subscribe to get the latest posts sent to your email.
Hi, I read your article, very interesting subject if you want to implement the SCD type one in reporting layer, please can you tell me where I can the link of the data source, or the excel file of contoso electronic
Hi Hamza,
You can find Microsoft sample databases here.
And here is the link to the AdventureWorks sample databases from Microsoft.
For Contoso however, I found this link which contains SQL Server backup file and SSAS Tabular backup file.
Hopefully that helps.
Cheers