
Incremental refresh, or IR, refers to loading the data incrementally, which has been around in the world of ETL for data warehousing for a long time. Let us discuss incremental refresh (or incremental data loading) in a simple language to better understand how it works.
From a data movement standpoint, there are always two options when we transfer data from location A to location B:
- Truncation and load: We transfer the data as a whole from location A to location B. If location B has some data already, we entirely truncate the location B and reload the whole data from location A to B
- Incremental load: We transfer the data as a whole from location A to location B just once for the first time. The next time, we only load the data changes from A to B. In this approach, we never truncate B. Instead, we only transfer the data that exists in A but not in B
When we refresh the data in Power BI, we use the first approach, truncation and load, if we have not configured an incremental refresh. In Power BI, the first approach only applies to tables with Import or Dual storage modes. Previously, the Incremental load was available only in the tables with either Import or Dual storage modes. But the new announcement from Microsoft about Hybrid Tables greatly affects how Incremental load works. With the Hybrid Tables, the Incremental load is available on a portion of the table when a specific partition is in Direct Query mode, while the rest of the partitions are in Import storage mode.
Incremental refresh used to be available only on Premium capacities, but from Feb 2020 onwards, it is also available in Power BI Pro with some limitations. However, the Hybrid Tables are currently available on Power BI Premium Capacity and Premium Per User (PPU), not Pro. Let’s hope that Microsft will change its licensing plan for the Hybrid Tables in the future and make it available in Pro.
I will write about Hybrid Tables in a future blog post.
When we successfully configure the incremental refresh policies in Power BI, we always have two ranges of data; the historical range and the incremental range. The historical range includes all data processed in the past, and the incremental range is the current range of data to process. Incremental refresh in Power BI always looks for data changes in the incremental range, not the historical range. Therefore, the incremental refresh will not notice any changes in the historical data. When we talk about the data changes, we are referring to new rows inserted, updated or deleted, however, the incremental refresh detects updated rows as deleting the rows and inserting new rows of data.
Benefits of Incremental Refresh #
Configuring incremental refresh is beneficial for large tables with hundreds of millions of rows. The following are some benefits of configuring incremental refresh in Power BI:
- The data refreshes much faster than when we truncate and load the data as the incremental refresh only refreshes the incremental range
- The data refresh process is less resource-intensive than refreshing the entire data all the time
- The data refresh is less expensive and more maintainable than the non-incremental refreshes over large tables
- The incremental refresh is inevitable when dealing with massive datasets with billions of rows that do not fit into our data model in Power BI Desktop. Remember, Power BI uses in-memory data processing engine; therefore, it is improbable that our local machine can handle importing billions of rows of data into the memory
Now that we understand the basic concepts of the incremental refresh, let us see how it works in Power BI.
Implementing Incremental Refresh Policies with Power BI Desktop #
We currently can configure incremental refresh in the Power BI Desktop and in Dataflows contained in a Premium Workspace. This blog post looks at the incremental refresh implementation within the Power BI Desktop.
After successfully implementing the incremental refresh policies with the desktop, we publish the model to Power BI Service. The first data refresh takes longer as we transfer all data from the data source(s) to Power BI Service for the first time. After the first load, all future data refreshes will be incremental.
How to Implement Incremental Refresh #
Implementing incremental refresh in Power BI is simple. There are two generic parts of the implementation:
- Preparing some prerequisites in Power Query and defining incremental policies in the data model
- Publishing the model to Power BI Service and refreshing the dataset
Let’s briefly get to some more details to quickly understand how the implementation works.
- Preparing Prerequisites in Power Query
- We require to define two parameters with DateTime data type in Power Query Editor. The names for the two parameters are RangeStart and RangeEnd, which are reserved for defining incremental refresh policies. As you know, Power Query is case-sensitive, so the names of the parameters must be RangeStart and RangeEnd.
- The next step is to filter the table by a DateTime column using the RangeStart and RangeEnd parameters when the value of the DateTime column is between RangeStart and RangeEnd.
Notes
- The data type of the parameters must be DateTime
- The datat tpe of the column we use for incremental refresh must be Int64 (integer) Date or DateTime.Therefore, for scenarios that our table has a smart date key instead of Date or DateTime, we have to convert the RangeStart and RangeEnd parameters to Int64
- When we filter a table using the RangeStart and RangeEnd parameters, Power BI uses the filter on the DateTime column for creating partitions on the table. So it is important to pay attention to the DateTime ranges when filtering the values so that only one filter condition must have an “equal to” on RangeStart or RangeEnd, not both
Sidenote
A Smart Date Key is an integer representation of a date value. Using a Smart Date Key is very common in data warehousing for saving storage and memory. So, the 20200809 integer value represents the 2020/08/09 date value. Therefore, if our source data is coming from a data warehouse, we are likely to have smart date keys in our tables. For those scenarios, we can use the following Power Query expression to generate smart date keys from DateTime values. I explain how to use the following expression later in this post.
Int64.From(DateTime.ToText(Your_DateTime_Value, "yyyyMMdd"))- Defining Incremental Refresh Policies: After we finished the initial preparations in Power Query, we require to define the incremental refresh policies on the Power BI data model in Power BI Desktop
- Publishing the model to Power BI Service
- Refreshing the published dataset in Power BI Service. We usually schedule automatic data refreshes on the Power BI Service. Incremental refresh means nothing if we do not frequently refresh the data after all.
Important Notes
- We have to know that nothing happens in Power BI Desktop after we successfully configured incremental refresh. All the magic happens after we publish the report to Power BI Service after we refresh the dataset for the first time. The Power BI Service generates partitions over the table with the incremental refresh. The partitions are defined based on our configuration in Power BI Desktop.
- After we refresh the dataset in Power BI Service for the first time, we will not be able to download the report from Power BI Service anymore. This constraint makes absolute sense. Imagine that we incrementally load billions of rows of data into a table. Even if we could download the file (which we cannot anyways) our desktop machines are not able to handle that much data. Remember, Power BI uses in-memory data processing engine and a table containing billions of rows of data would require hundreds of gigabytes of RAM. So that’s why it does not make sense to download a report configured with an incremental refresh from Power BI Desktop.
- The fact that we cannot download the report from the service raises another concern for Power BI development and future support. If in the future, we require to make some changes in the data model then we have to use some other tools than Power BI Desktop, such as Tabular Editor, ALM Toolkit or SQL Server Management Studio (SSMS) to deploy the changes to the existing dataset without overwriting the existing dataset. Otherwise, if we make all changes in Power BI Desktop and simply publish the changes back to the service and overwrite the existing dataset, then all the partitions created on the existing dataset and their data are gone. To be able to connect to an existing dataset using any of the mentioned tools, we have to use XMLA endpoints which are available only in Premium Capacities, Premium Per User or Embedded Capacities; not in Power BI Pro. So, be aware of that restriction if you are planning to implement incremental refresh with Pro license.
How the Incremental Refresh Works #
It is important to know how the incremental refresh policies work to define them properly. After we publish the model to the Power BI Service, the service creates multiple partitions over the table with incremental policies based on year, month, and day.
Based on how we define our incremental policy, those partitions will be automatically refreshed (if we schedule automatic data to refresh on the service). Over time, some of those partitions will be dropped, and some will be merged with other partitions.
We must know some terminologies to ensure we understand how the incremental refresh works.
Terminologies
- Historical Range (Period): When we define an incremental policy, we always define a date range that we would like to retain the data. For instance, we say, we require to retain 10 years of data. That 10 years of data will not change at all. Over time, the old partitions that go out of range will be dropped, and some other partitions will move to the historical range.
- Incremental Range (Period): Another vital part of an incremental policy is the incremental range which is the date range that the data changes in the data source. Therefore, we require to refresh that part of the data more frequently. For example, we may require to refresh one month of data, while we archive 10 years of data that fall into the historical range.
Both historical and incremental ranges roll forward over time. When new partitions are created, the old partitions that no longer belong to the incremental range become historical partitions. As mentioned before, the partitions are created based on the year, month, day hierarchy. So historical partitions become less granular and get merged.
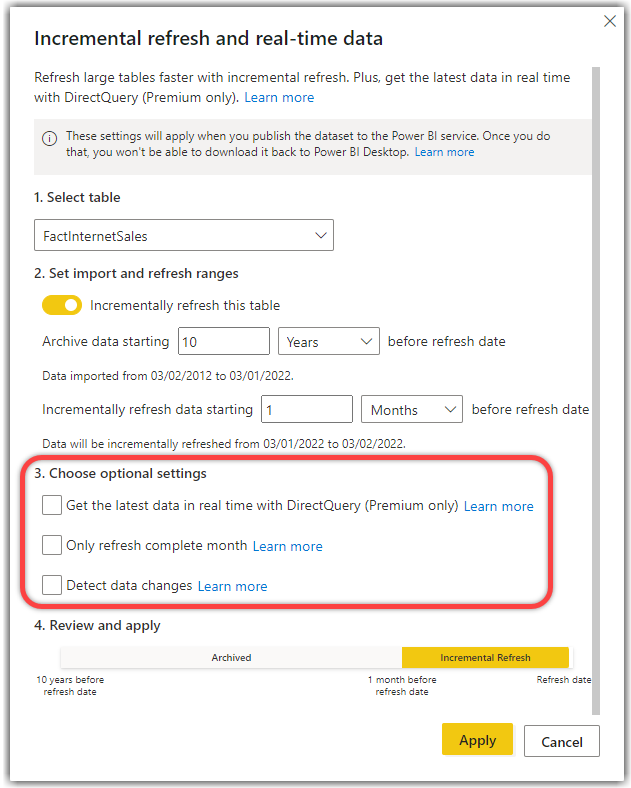
The following image shows an incremental refresh policy that:
- Stores rows if the last 10 years
- Refreshes rows in the 2 days
- Only refresh complete days = True
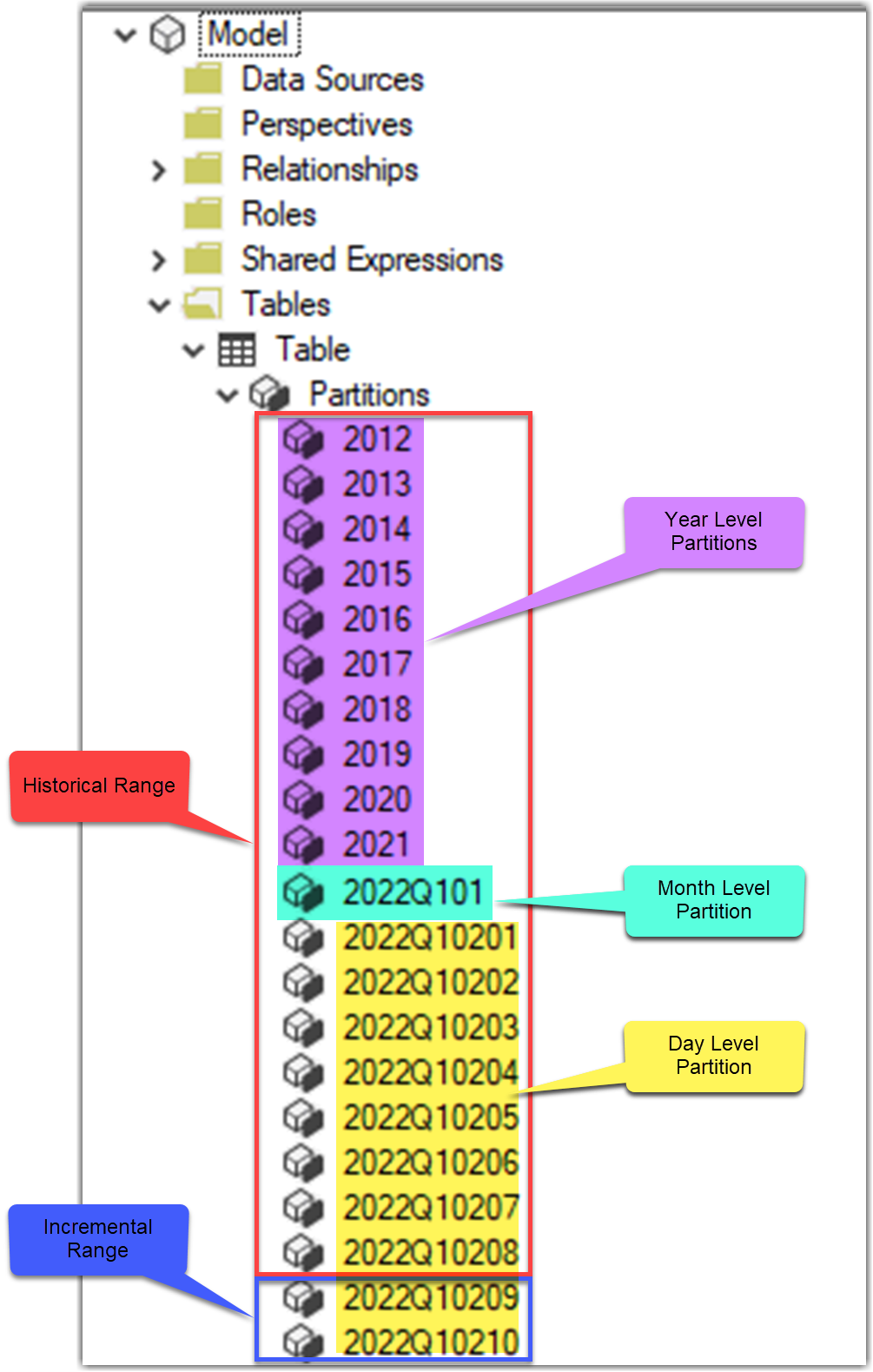
We can imagine that when data is refreshed on 1 February 2022, all January 2022 data is refreshed, all created partitions at the day level (2022Q10101, 2022Q10102, 2022Q10103…), merged together and became historical (2022Q101). Similarly, all month-level partitions for 2021 are merged.
With that, let us implement incremental refresh.
Implementing Incremental Refresh Using DateTime Columns #
Let’s think about a scenario in that we require to implement an incremental refresh policy to store 10 years of data plus the data up to the current date, and then the data of the last 1-month refresh incrementally. For this example, I use the famous AdventureWorksDW2019 SQL Server database. You can download the SQL Server backup file from here.
Follow these steps to implement the preceding scenario:
- In Power Query Editor, get data from the FactInternetSales table from AdventureWorksDW2019 from SQL Server and rename it Internet Sales
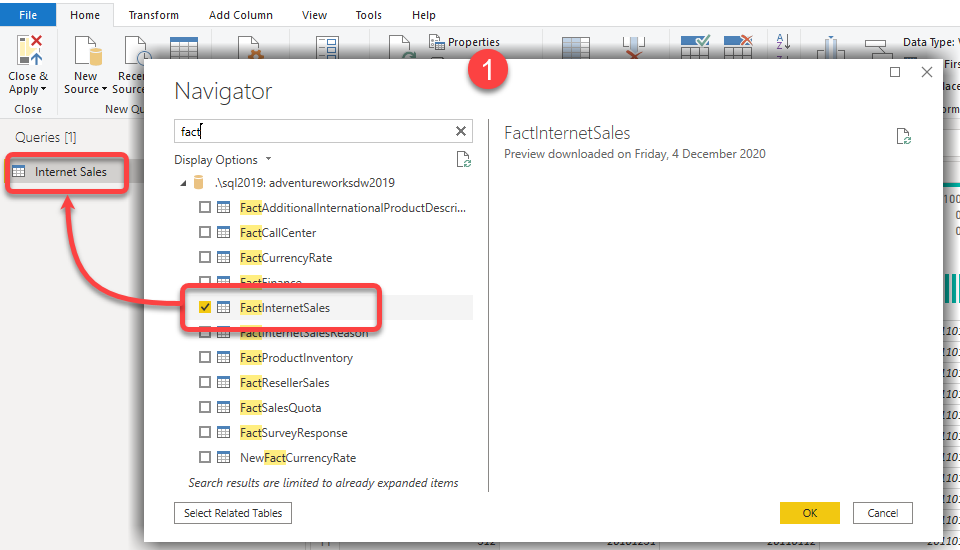
- Define RangeStart and RangeEnd parameters with DateTime type. Set the Current Value of the parameters as follows:
- Current Value of RangeStart: 1/12/2010 12:00:00 AM
- Current Value of RangeEnd: 31/12/2010 12:00:00 AM
Note
Set the Current Value of the parameters that work for your scenario. Keep in mind that these values are only useful at development time. So, after applying the filters on the next steps, the Internet Sales table in Power BI Desktop will only include the values between the RangeStart and RangeEnd.
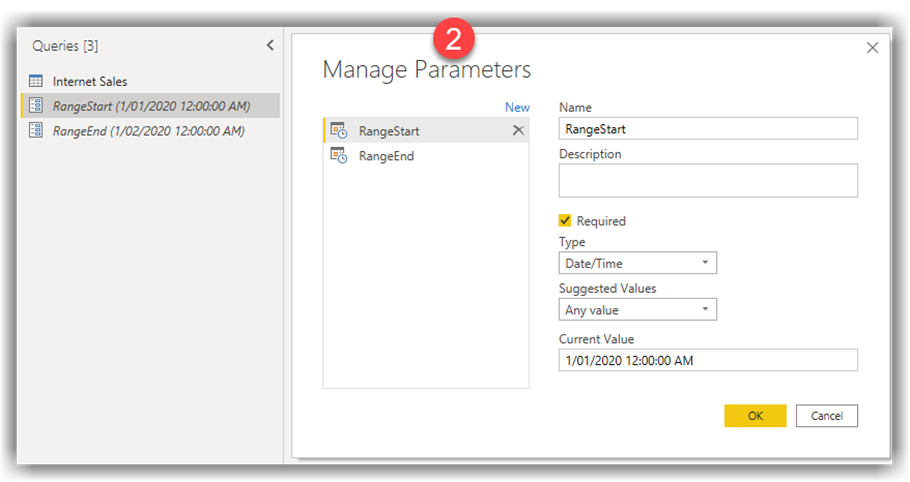
- Filter the OrderDate column as shown in the following image. Note how we defined the filter conditions.
Note
The above setting would be different for the scenario where our table has a Smart Date Key. I will explain the “how” later in this post.
- Click Close & Apply button to import the data into the data model
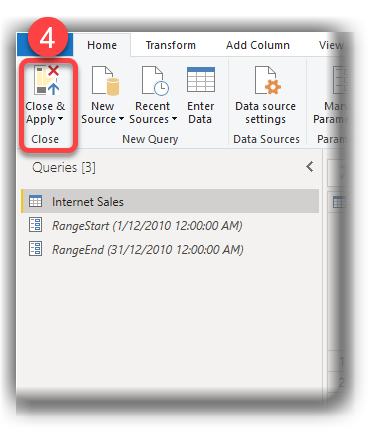
- Right click the Internet Sales table and click Incremental refresh. The Incremental refresh is available in the context menu in the Report view, Data view or Model view
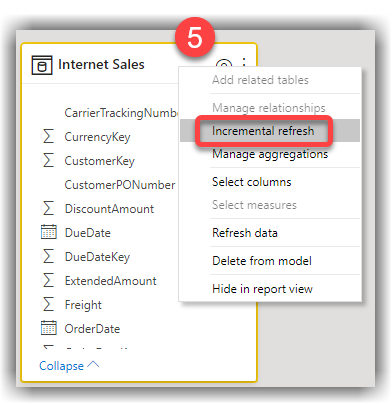
- Take the following steps on the Incremental refresh and real-time data window:
- a. Toggle on the Incremental refresh this table
- b. Set the Archive data starting setting to 10 Years
- c. Set the Incrementally refresh data starting setting to 1 Month
- d. Leave all Optional settings unchecked. I will explain what they are and when to use them later in this post.
- e. Click Apply
So far, we configured incremental refresh in Power BI Desktop based on a column with DateTime data type. What if we do not have a DateTime column in the table we require the data to refresh incrementally? Let’s see how we can implement it.
Implementing Incremental Refresh Using Smart Date Keys #
As mentioned before, we are likely to have a Smart Date Key in the fact table in the scenarios where the data source is a data warehouse. So the table looks like the following image:
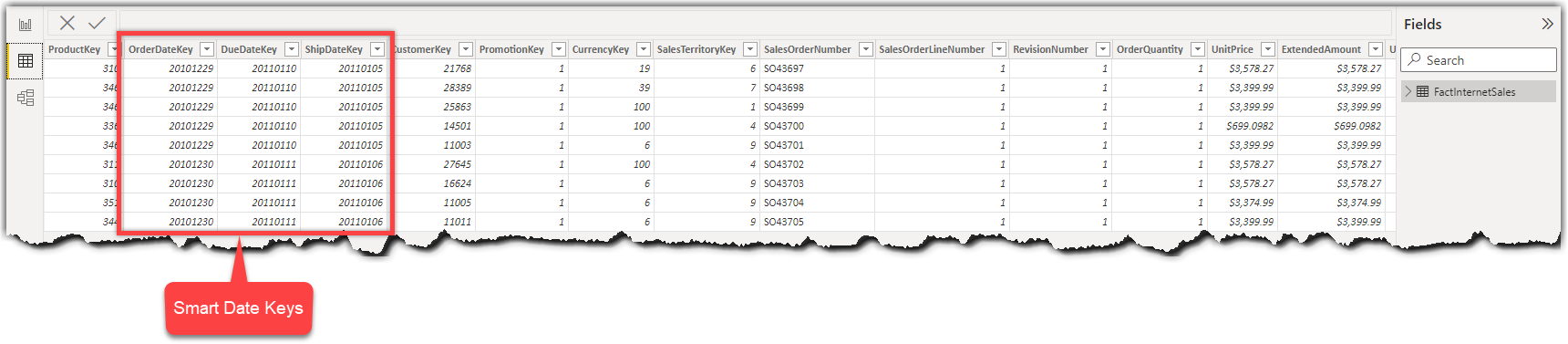
As shown in the preceding image, the OrderDateKey, DueDateKey, and ShipDateKey are all integer values representing Date values. Let us implement the incremental refresh on top of the OrderDateKey.
As a matter of fact, all the steps we previously took are valid, the only step that is a bit different is the step 3 when we filter the Internet Sales table using the incremental refresh parameters. Let us open Power Query Editor and have a look.
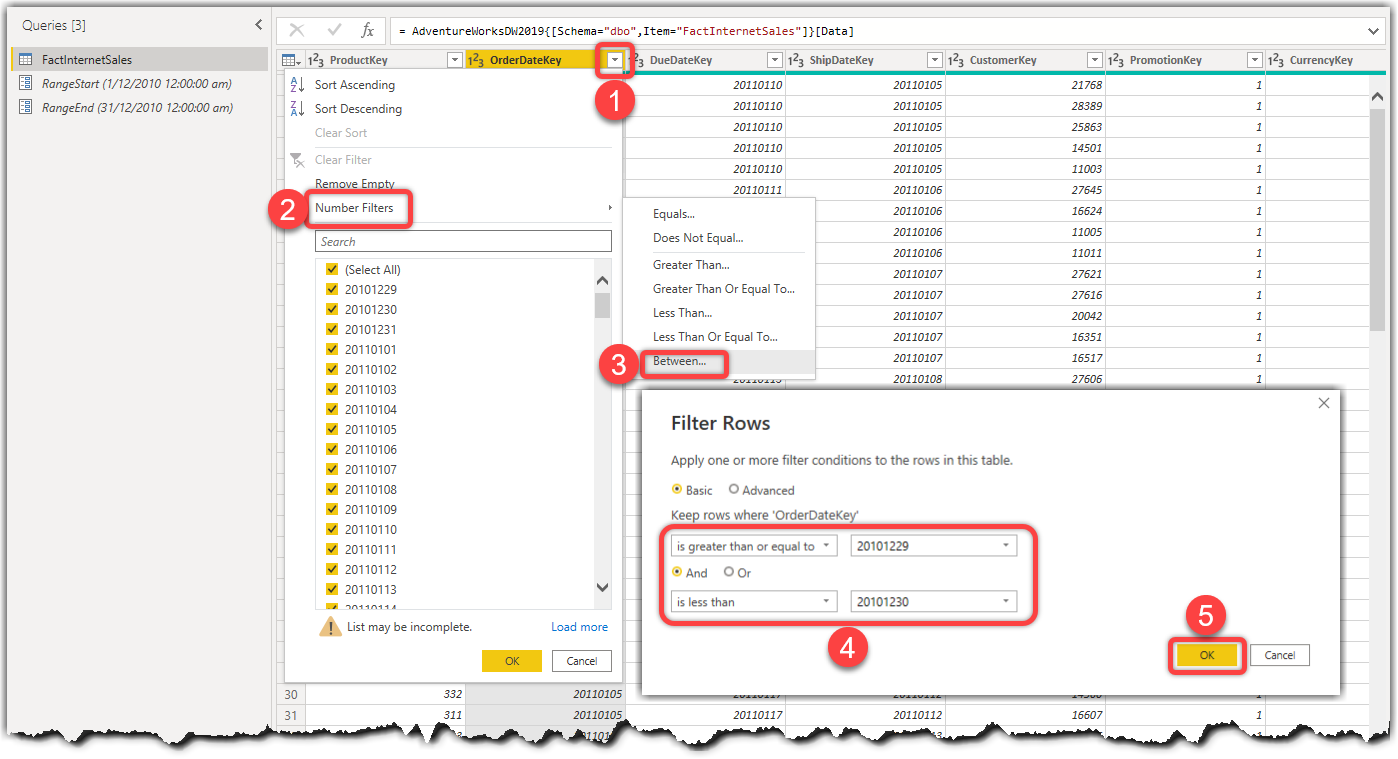
- Click the filter dropdown of the OrderDateKey
- Hover over Number Filters
- Click Between
- Ensure to set the range, so it is greater than or equal to a dummy integer value and is less than another dummy value
- Click OK
- Replace the dummy integer values of the Filtered Rows step with the following expressions
- Replace the 20201229 with
Int64.From(DateTime.ToText(RangeStart, "yyyyMMdd")) - Replace the 20201230 with
Int64.From(DateTime.ToText(RangeEnd, "yyyyMMdd"))
- Replace the 20201229 with
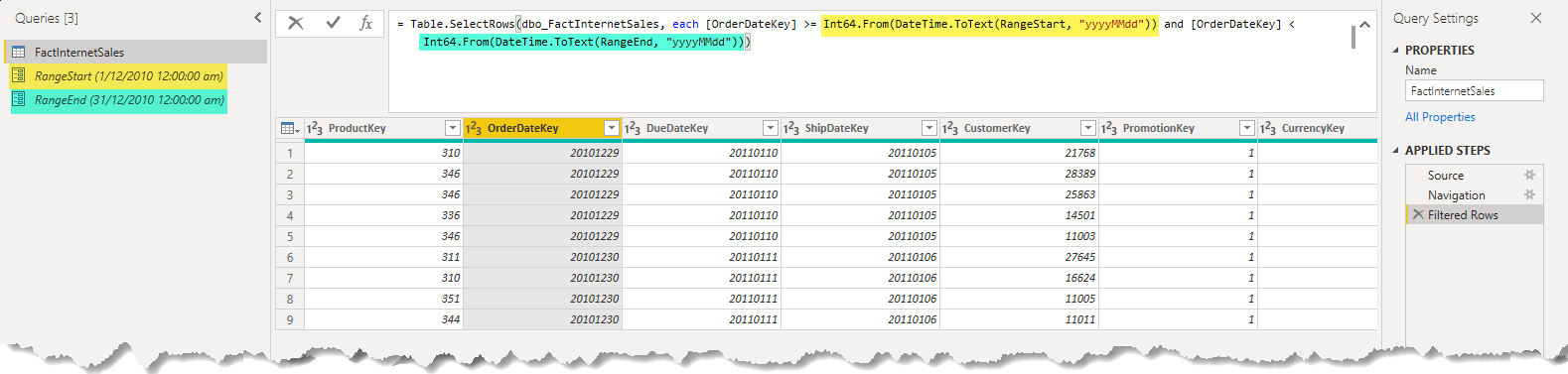
Now we can click the Close & Apply button to load the data into the data model. The rest would be the same as we saw previously to configure the incremental refresh in the Power BI Desktop.
Now let us have a look at the Optional Settings when configuring the incremental refresh.
Optional Settings in Incremental Refresh Configuration #
As we previously saw, the Incremental refresh and real-time data window contains a section dedicated to Optional Settings. These optional settings are:
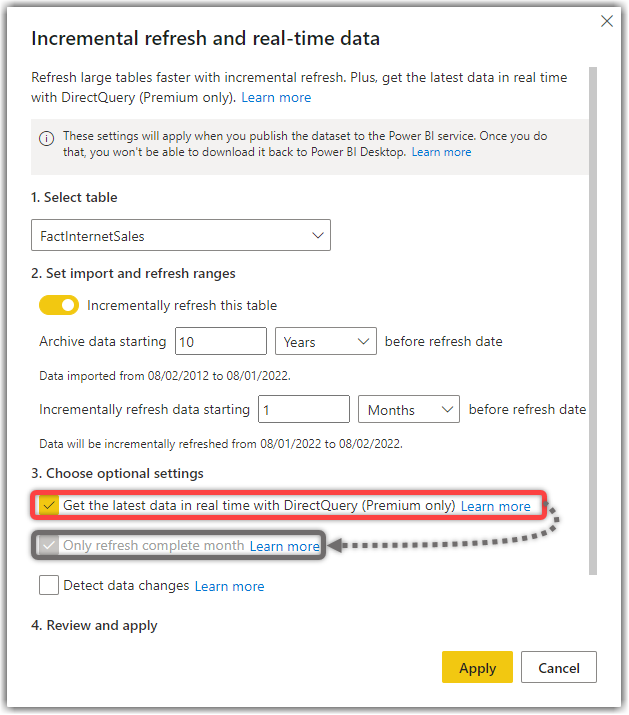
- Get the latest data in real-time with DirectQuery (Premium only): This feature enables the latest partition of data to connect over Direct Query back to the source system. This feature is a Premium-only feature and is currently under public preview. So, can try using this feature, but it is highly recommended not to use a preview feature on production environments. I will write a blog post about Hybrid Tables, their pros and cons, and current limitations in the Implementing Incremental Refresh series in near future.
- Only refresh complete month: The name of this option depends on our configuration on section 2 of the Incremental refresh and real-time data window (look at the above screenshot). If we set the Incrementally refresh data starting X Days, then this option would be Only refresh complete days. In our sample, it is Only refresh complete days. Now let’s see what it is about. This option ensures that all rows for the entire period, depending on what we selected in the previous settings in section 2, are included when the data refreshes. Therefore, the refresh includes all data of the month only when the month is completed. For instance, we can refresh June’s data in July. Our sample does not require this functionality, so we left this option unticked. Please note that if we select to get the latest data in Direct Query, which makes the table to be a so-called Hybrid Table (the previous option), then this option is mandatory and greys out by default, as shown in the image below:
- Detect data changes: In many data integration and data warehousing processes, we add some auditing columns to the tables to some useful metadata, such as Last Modified Date, Last Modified By, Activity, Is Processed, and so on. If you have a DateTime column indicating the data changes (such as Last Modified Date), the Detect data changes option would be helpful. When we enable this option, we can select the desired audit column, which should not be the same column used to create the partitions with the RangeStart and RangeEnd parameters. In each scheduled refresh period, Power BI considers the maximum value of this column against the incremental range to detect if any changes happened in that period. So if there are no changes, the partition doesn’t refresh. We can undertake many refinement techniques with this option via XMLA endpoints that I will cover in a future blog post of the Implementing Incremental Refresh series. But in our sample in this blogpost, we do not have any auditing columns in our source table; therefore we leave this option unticked.
Testing the Incremental Refresh #
So far, we implemented the incremental refresh. The next step is to test it. As mentioned before, we cannot see anything in Power BI Desktop. The only change we can see is that the FactInternetSales data is being filtered. To test the solution, we have to take two more steps:
- Publishing the model to Power BI Service
- Refreshing the dataset in the Service
- Testing the Incremantal Refresh
Publishing the model to Power BI Service #
When we say publishing a model to Power BI Service, we are indeed referring to publishing the Power BI Desktop report file (PBIX) which contains the data model and the report itself (if any) to the Power BI Service. There are multiple methods to do so which are out of the scope of this post. The most popular method is publishing the model from the Power BI Desktop itself as follows:
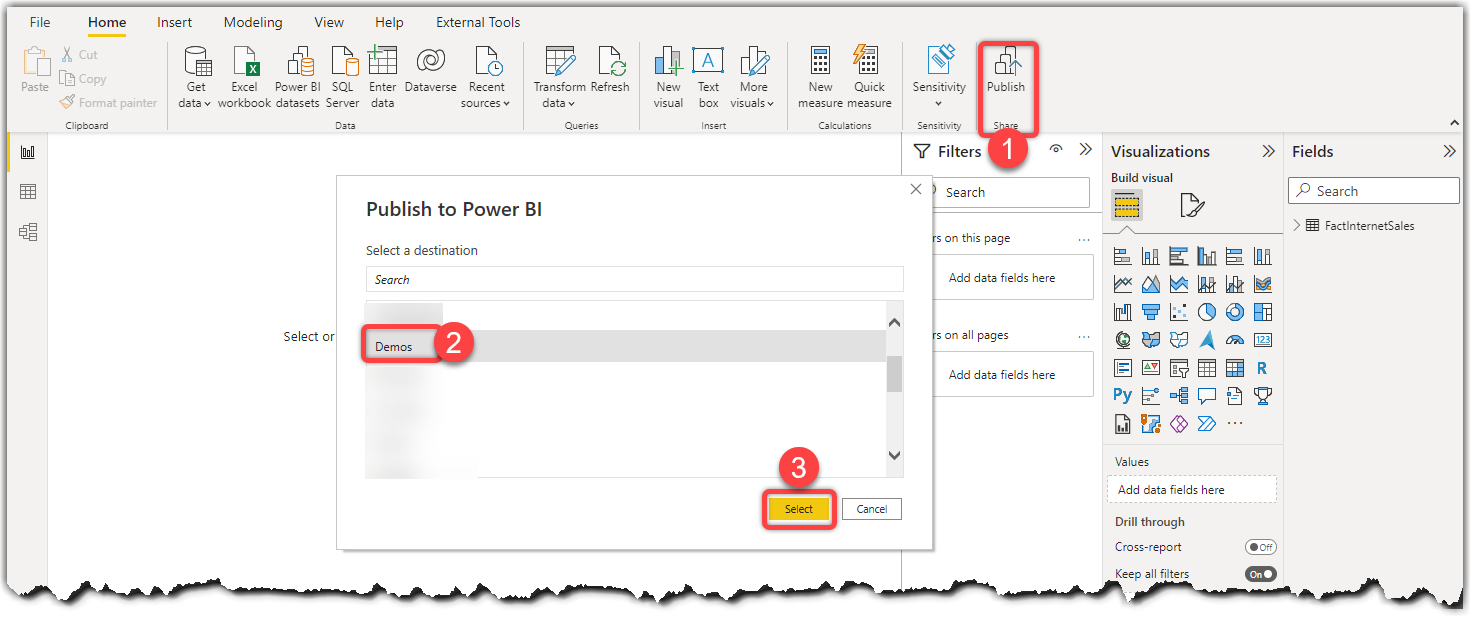
- Click the Publish button from the Home tab from the ribbon bar
- Select the Workspace you’d like to publish the model to
- Click Select
Refreshing the dataset in the Service #
Now that we published the model to the service, we have to go to the service and refresh the dataset. If you have used an on-premises data source like what we have done in our sample in this blog post, then you have to configure On-premises Data Gateway. You can read more about the On-premises Data Gateway configuration here. With that, let’s head to our Power BI Service and refresh the dataset:
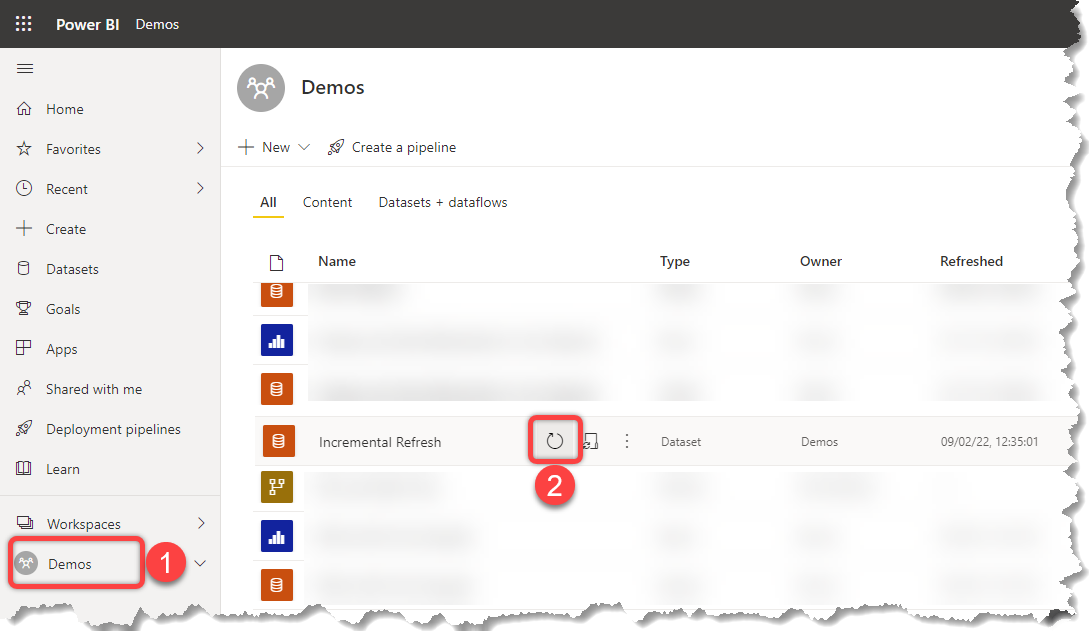
- Open Power BI Service and navigate to the desired Wrokspace
- Hover over the dataset and click the Refresh button
As mentioned before, after we refresh the dataset in Power BI Service for the first time, we will not be able to download the report from Power BI Service anymore. Also, keep in mind that the first data refresh takes longer than the future refreshes.
Testing the Incremental Refresh #
So far, we’ve configured the incremental refresh and published the data model to the Power BI Service. At this point, a Power BI administrator should take over this process to schedule automatic refreshes, configure the On-premises Data Gateway when necessary, enter data sources’ credentials, and more. These settings are outside the scope of this post, so I leave them to you. So, let’s assume the Power BI administrators have completed these settings in the Power BI Service.
Currently, there is no way that we can visually see the created partitions either in Power BI Desktop or Power BI Service. However, we can use other tools such as SQL Server Management Studio (SSMS), DAX Studio or Tabular Editor to see the partitions created for the incremental data refresh. However, to be able to use those tools, we must have either a Premium or an Embedded capacity or a Premium Per User (PPU) to be able to connect the desired workspace in Power BI Service through XMLA Endpoints to visually see the partitions created on the table. But, there is one way to test the incremental refresh even with the Power BI Pro license if we do not have a Premium capacity or PPU.
Testing Incremental Refresh with Power BI Pro License
If you recall, when we implemented the incremental refresh prerequisites in Power Query, we filtered the table’s data on the OrderDate column with the RangeStart and RangeEnd parameters. In our sample we filtered the data when the current value of the parameters are:
- Current Value of RangeStart:1/12/2010 12:00:00 AM
- Current Value of RangeEnd: 31/12/2010 12:00:00 AM
Therefore, if the incremental refresh did not go through, we must only see the data for December 2010. So, we require to create a new report either in Power BI Desktop or Power BI Service (or a new report page if there is an existing report already) connect to the dataset, put a table visual on the reporting canvas and look at the data. I create my report the service and here is what I see:
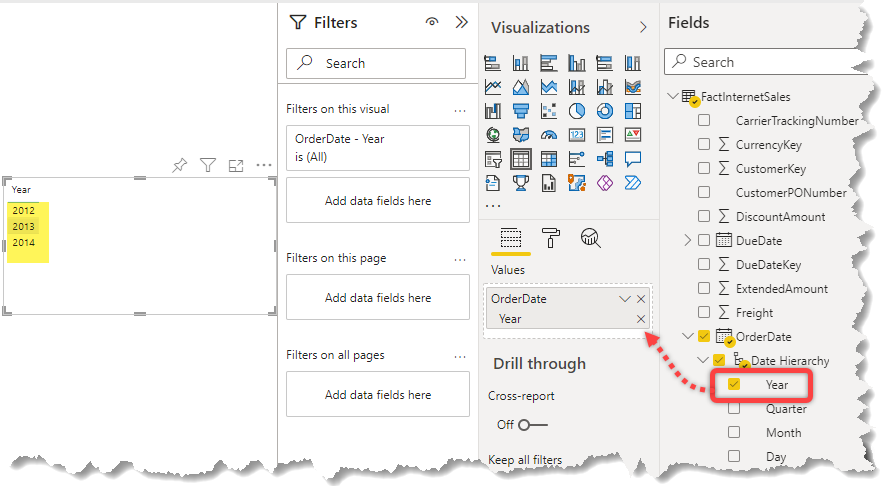
As you see the dataset contains data between 2012 to 2014. I bet you noticed I did not disable the Auto Date/Time feature which is a sin from a data modelling best practices point of view, but, this is for testing only. So let’s not be worried about that for the moment. You can read more about Auto Date/Time considerations here.
With that, let’s see what happened here.
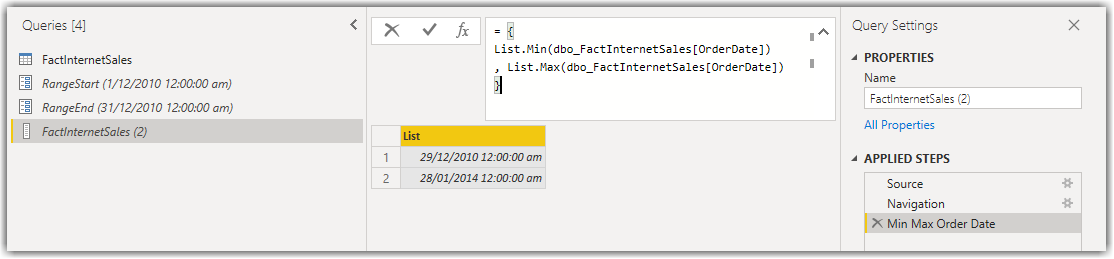
If we look at our original report file in Power BI Desktop connected to the data source, before the filtering data step in Power Query, we see that the FactInternetSales table contains data with OrderDate between 29/12/2010 12:00:00 am and 28/01/2014 12:00:00 am.
The following screenshot shows that I duplicated the FactInternetSales in Power Query and created a list containing minimum and maximum values of the OrderDate column:
So, the reason that the FactInternetSales table in the Power BI Service dataset starts from 2012 means that the incremental refresh was successful. If you recall, we configured the incremental refresh to retain the data for 10 years only. Let’s have a look at the Incremental Refresh windows again.
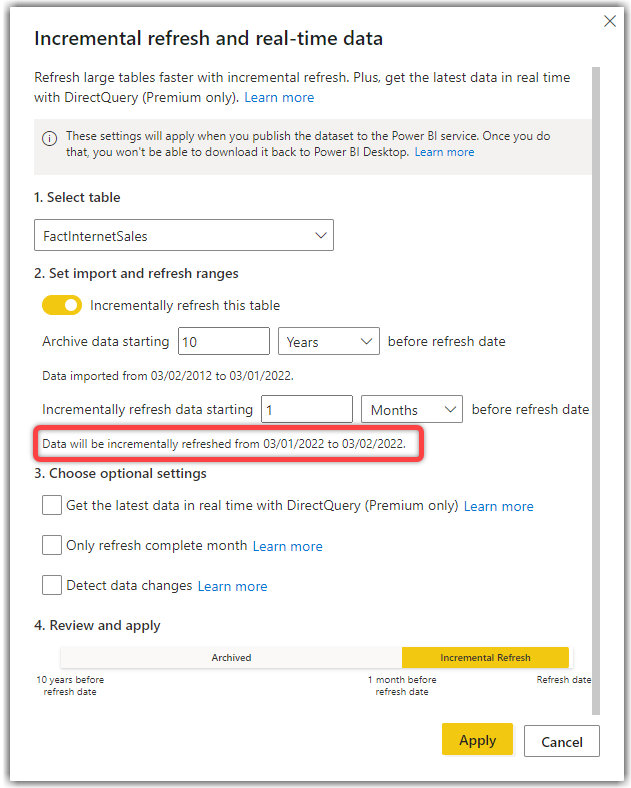
It is Feb 2022 now, and we configured the incremental refresh period for 1 month, which covers Jan 2022 to Feb 2022 depending on the day we are refreshing the data; therefore, I would expect my dataset to contain the data from Jan 2012 onwards.
So to confirm it, I add the Month level of the auto date/time hierarchy to the visualisation. Here are the results:
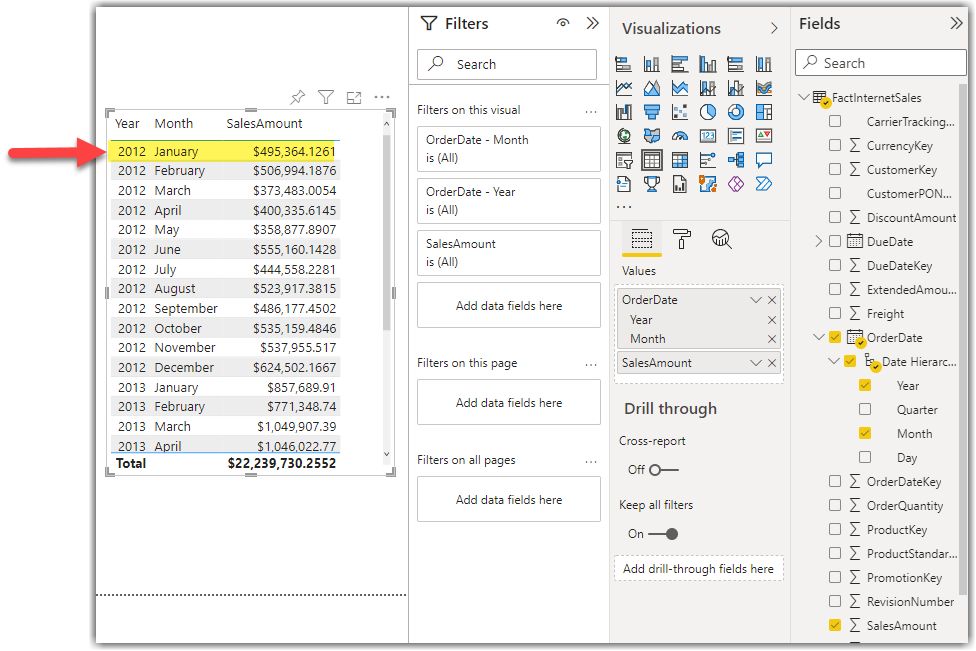
So, I am confident that my incremental refresh policy is working as expected.
Now, let’s see how easy it is to verify the incremental refresh in Power BI Premium capacity, Power BI Embedded and Premium Per user.
Testing Incremental Refresh with Power BI Premium/Embedded/PPU Licenses
Testing the incremental refresh is very easy when we have a premium or embedded licensing plan. Using XMLA Endpoints, we can quickly connect to a Workspace backed by our premium or embedded plan and look at the table’s partitions. This section quickly shows you how to use the most popular tools to verify that the incremental refresh happened and what partitions are created for us behind the scene. But, before we use any tools, we have to obtain the premium URL from our Workspace that we will use in the tools later. The following steps show how to do so:
- Head to the desired Workspace on the service
- Click Settings
- Click the Premium tab
- Click the Copy button to copy the Workspace Connection
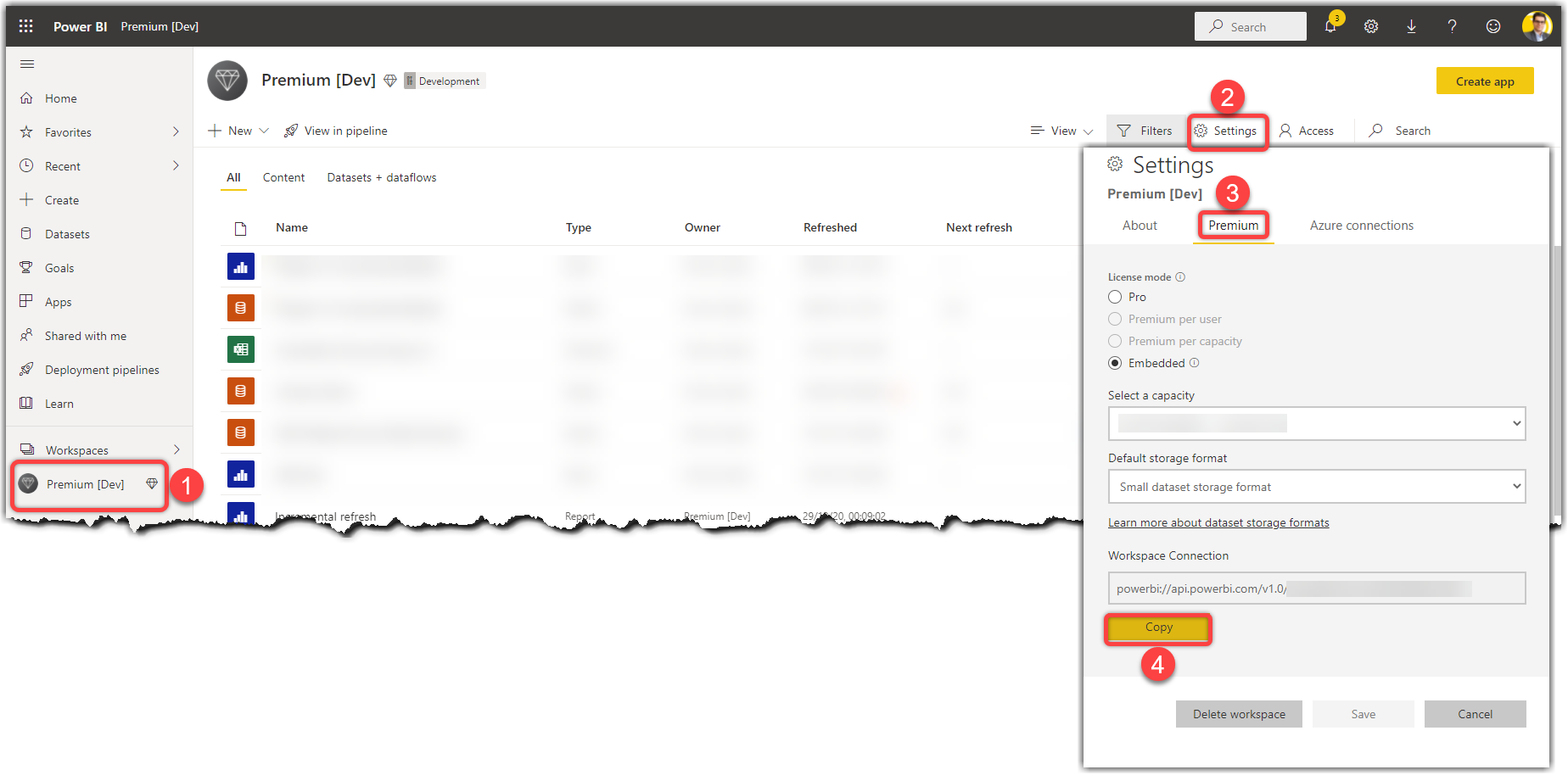
Now that we have the Workspace Connection handy, let’s see how we can use it in different tools.
Testing Incremental Refresh with Tabular Editor 2.xx
Tabular Editor is one of the most fantastic development tools related to Power BI, SSAS Tabular and Azure Analysis Services (AAS) built by Daniel Otykier. The tool comes in two flavours, Tabular Editor 2.xx and Tabular Editor 3. The Tabular Editor 2.xx is the free version of the tool, and version 3 of the tool is commercial, but believe me, it is worth every cent. If you do not already know the tool, I strongly advise you to download the 2.xx version and learn how to use it to boost your development experience.
Let’s get back to the subject, to see the partitions created by the incremental refresh configuration follow these steps:
- In Tabular Editor 2.xx, click the Open Tabular Model button
- Paste the Workspace Connection (the Premium URL we copied) on the Server section
- Click OK. This navigates you to pass your credentials
- Select the desired dataset
- Click OK
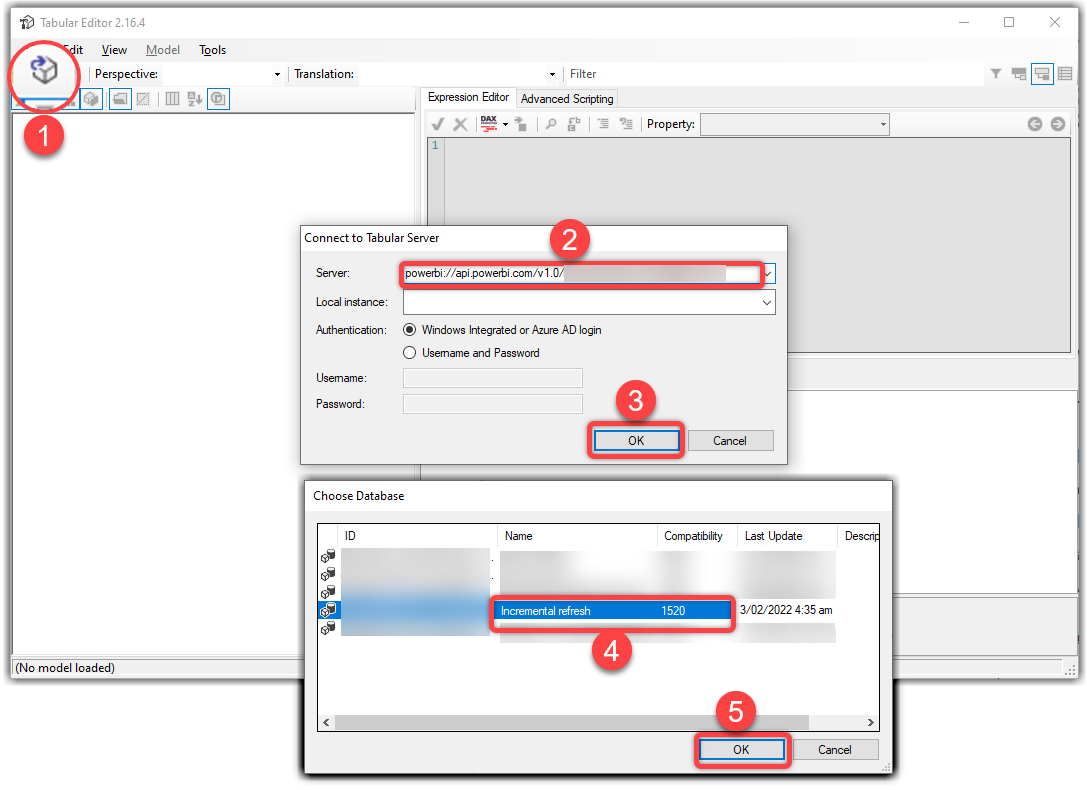
- Expand Tables
- Expand FactInternetSales (the table with incremental refresh)
- Expand Partitions
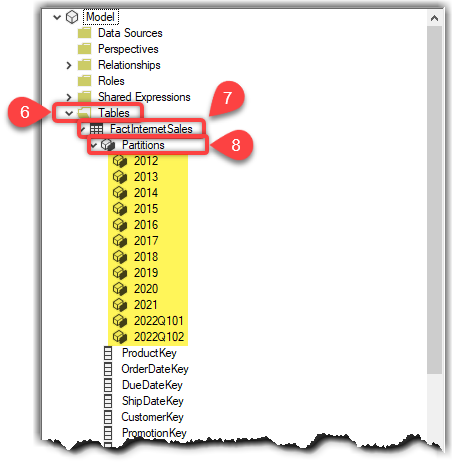
The partitions are highlighted in the preceding screenshot.
Testing Incremental Refresh with DAX Studio
DAX Studio is another amazing community tool available for free from SQL BI managed by our Italian friends, Marco Russo and Alberto Ferrari. Seeing the partitions in DAX Studio is simple:
- In DAX Studio, paste the Workspace connection on the Tabular Server section
- Click Connect and enter your credentials
- From the left pane, select the desired dataset from the dropdown list
- Click the Advanced tab from the ribbon
- Click the View Metrics button
- From the Vertipaq Analyzer Metrics pane, click Partitions
- Expand FactInternetSales (the table with incremental refresh)
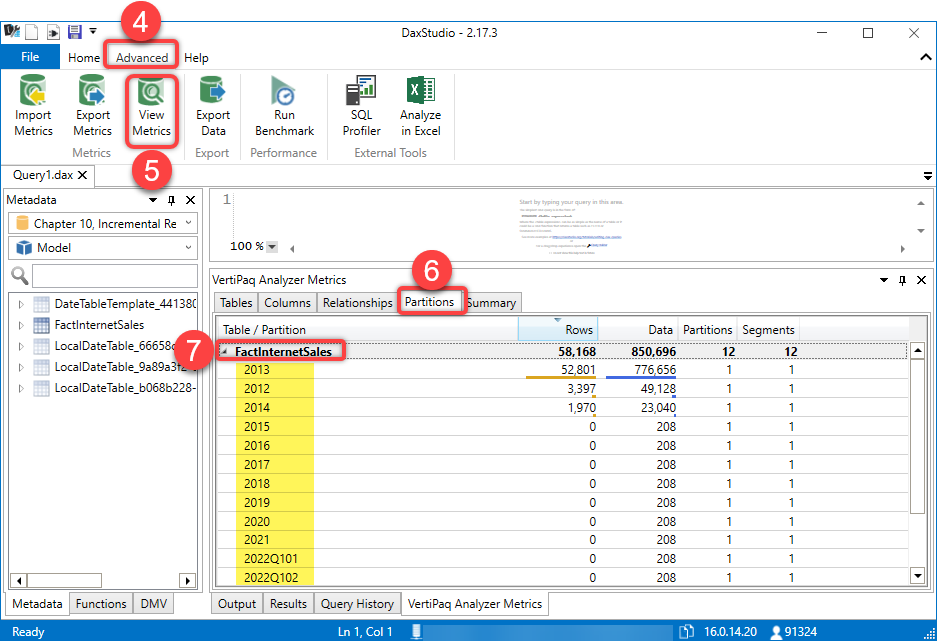
The partitions are highlighted.
Testing Incremental Refresh with SQL Server Management Studio (SSMS)
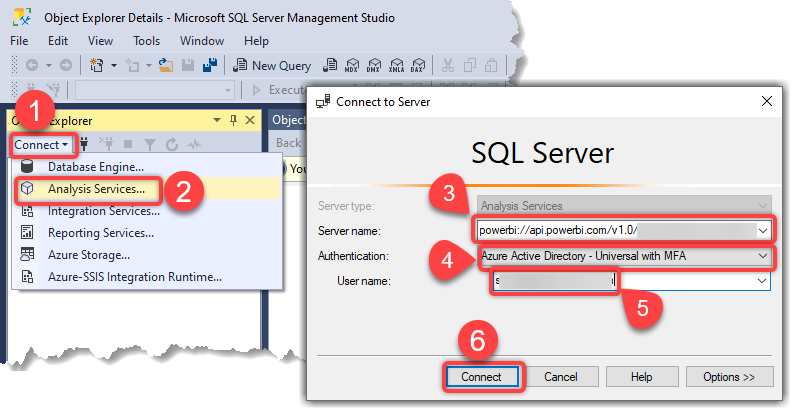
SQL Server Management Studio (SSMS) has been around for many years. Many SQL Server developers, including SSAS Tabular Models developers, still use SSMS on a daily basis. SSMS is a free tool from Microsoft. With SSMS, we can connect to and fine-tune the partitions of tables contained in a premium dataset. Let’s see how we can see a Power BI dataset table’s partitions in SSMS. The following steps show how to do so:
- On SSMS, from the Object Explorer pane, click the Connect dropdown
- Click Analysis Services
- Paste the Workspace Connection to the Server name section
- Select Azure Active Directory- Universal with MFA from the Authentication dropdown
- Enter your User name
- Click Connect. At this point you have to pass your credentials
- We are now connected to our premium Workspace. Expand Databases
- Expand the desired dataset
- Expand Tables
- Right-click the desired tabel (FactInternetsales in our sample)
- Click Partisions
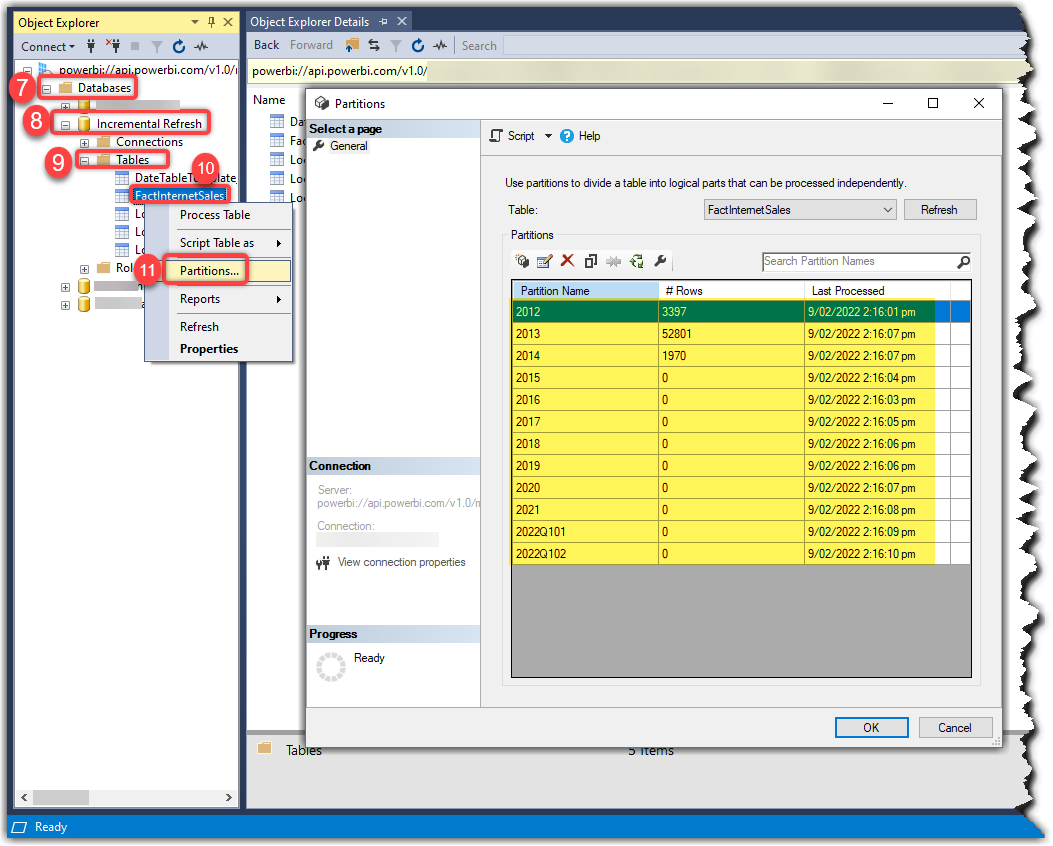
The partitions are highlighted in the preceding screenshot.
That was it for the first part of this series. Hopefully, you find this post helpful. The next blog post will look into Hybrid Tables, their benefits, limitations, and use cases.
Please feel free to enter any comments or feedback in the comments section below.
Discover more from BI Insight
Subscribe to get the latest posts sent to your email.
Hi Soheil, really a great compliment for this outstanding post. Looking forward to the next ones. One question. If I just refresh the data on a daily basis, why do I need then to check “Set the Incrementally refresh data starting setting to 1 Month”? Is the refresh mechanisme by the way automatically using days/monts/years when partitioning?
Detect Data Changes – please brief about this option.. why we should not use the same column for partitions.
Hi Siva,
Welcome to biinsight.com.
Great question!
As explained before, when we use the Detect Data Changes, the incremental refresh takes the maximum of the column and looks for the changes after that. Therefore, the partition will never refresh as the maximum date is always the latest in the incremental refresh policy.
I hope that clears out the point.
Cheers.
Hi Soheil,
Thank you for this helpful post. One question, setting up the On-premises Data Gateway must for the incremental refresh to work? I am getting an error
“Scheduled refresh is disabled because at least one data source is missing credentials. To start the refresh again, go to this dataset’s settings page and enter credentials for all data sources. Then reactivate scheduled refresh.”
I am trying to load the data from excel files in my local folder.
Hello Souhail
Where is part2,Part3,…
It would be really great if you could write similar articles for the cases of Dataflows and Datamarts
Hi there.
I am yet to write part 2, sorry for the delay. And… sure thing, I will put Dataflows and Datamarts in my writing list.
Thanks for this very detailed article on incremental refresh.
However, I’m unclear on how incremental refresh is a valid/practical option for Pro workspaces.
These 3 statements below kind of summarize where my confusion is:-
1. Incremental refresh can be setup in a Pro workspace
2. You can’t publish changes to a model setup with incremental refresh without using 3rd partly tools like Tabular editor, ALM toolkit which need XMLA endpoint.
3. Pro workspaces cannot be accessed through XMLA endpoint
In effect, one can’t practically use incremental refresh in Pro workspaces right?
Could you please clarify.
Hi Vivek,
Thank you for reaching out with your question.
You’ve summarised the situation quite accurately, and I appreciate your focus on the practical aspect of using incremental refresh.
In technical terms, it is indeed possible to set up incremental refresh on Pro workspaces. However, as you rightly pointed out, there are some limitations when it comes to making changes and publishing them. In order to publish changes to a model with incremental refresh, you would require third-party tools like Tabular Editor or ALM Toolkit, which rely on XMLA endpoints which is a Premium feature.
Unfortunately, Pro workspaces do not support access through XMLA endpoints, which makes the process a bit more challenging.
In a real-world scenario where business requirements evolve, this limitation can become a challenge. While incremental refresh can be technically implemented in Pro workspaces, going beyond the simplest scenarios require a Premium Dataset.
In conclusion, your observation is correct. Implementing incremental refresh in Pro workspaces may not be as practical as one would hope, especially when considering future changes and updates to the solution.
I hope this clarifies the situation for you. If you have any more questions or need further assistance, feel free to ask.