
In the two previous posts of the Incremental Refresh in Power BI series, we have learned what incremental refresh is, how to implement it, and best practices on how to safely publish the semantic model changes to Microsoft Fabric (aka Power BI Service). This post focuses on a couple of more best practices in implementing incremental refresh on large semantic models in Power BI.
Note
Since May 2023 that Microsoft announced Microsoft Fabric for the first time, Power BI is a part of Microsoft Fabric. Hence, we use the term Microsoft Fabric throughout this post to refer to Power BI or Power BI Service.
The Problem
Implementing incremental refresh on Power BI is usually straightforward if we carefully follow the implementation steps. However in some real-world scenarios, following the implementation steps is not enough. In different parts of my latest book, Expert Data Modeling with Power BI, 2’nd Edition, I emphasis the fact that understanding business requirements is the key to every single development project and data modelling is no different. Let me explain it more in the context of incremental data refresh implementation.
Let’s say we followed all the required implementation steps and we also followed the deployment best practices and everything runs pretty good in our development environment; the first data refresh takes longer, we we expected, all the partitions are also created and everything looks fine. So, we deploy the solution to production environment and refresh the semantic model. Our production data source has substantially larger data than the development data source. So the data refresh takes way too long. We wait a couple of hours and leave it to run overnight. The next day we find out that the first refresh failed. Some of the possibilities that lead the first data refresh to fail are Timeout, Out of resources, or Out of memory errors. This can happen regardless of your licensing plan, even on Power BI Premium capacities.
Another issue you may face usually happens during development. Many development teams try to keep their development data source’s size as close as possible to their production data source. And… NO, I am NOT suggesting using the production data source for development. Anyway, you may be tempted to do so. You set one month’s worth of data using the RangeStart and RangeEnd parameters just to find out that the data source actually has hundreds of millions of rows in a month. Now, your PBIX file on your local machine is way too large so you cannot even save it on your local machine.
This post provides some best practices. Some of the practices this post focuses on require implementation. To keep this post at an optimal length, I save the implementations for future posts. With that in mind, let’s begin.
Best Practices
So far, we have scratched the surface of some common challenges that we may face if we do not pay attention to the requirements and the size of the data being loaded into the data model. The good news is that this post explores a couple of good practices to guarantee smoother and more controlled implementation avoiding the data refresh issues as much as possible. Indeed, there might still be cases where we follow all best practices and we still face challenges.
Note
While implementing incremental refresh is available in Power BI Pro semantic models, but the restrictions on parallelism and lack of XMLA endpoint might be a deal breaker in many scenarios. So many of the techniques and best practices discussed in this post require a premium semantic model backed by either Premium Per User (PPU), Power BI Capacity (P/A/EM) or Fabric Capacity.
The next few sections explain some best practices to mitigate the risks of facing difficult challenges down the road.
Practice 1: Investigate the data source in terms of its complexity and size #
This one is easy; not really. It is necessary to know what kind of beast we are dealing with. If you have access to the pre-production data source or to the production, it is good to know how much data will be loaded into the semantic model. Let’s say the source table contains 400 million rows of data for the past 2 years. A quick math suggests that on average we will have more than 16 million rows per month. While these are just hypothetical numbers, you may have even larger data sources. So having some data source size and growth estimation is always helpful for taking the next steps more thoroughly.
Practice 2: Keep the date range between the RangeStart and RangeEnd small #
Continuing from the previous practice, if we deal with fairly large data sources, then waiting for millions of rows to be loaded into the data model at development time doesn’t make too much sense. So depending on the numbers you get from the previous point, select a date range that is small enough to let you easily continue with your development without needing to wait a long time to load the data into the model with every single change in the Power Query layer. Remember, the date range selected between the RangeStart and RangeEnd does NOT affect the creation of the partition on Microsoft Fabric after publishing. So there wouldn’t be any issues if you chose the values of the RangeStart and RangeEnd to be on the same day or even at the exact same time. One important point to remember is that we cannot change the values of the RangeStart and RangeEnd parameters after publishing the model to Microsoft Fabric.
Practice 3: Be mindful of number of parallelism #
As mentioned before, one of the common challenges arises after the semantic model is published to Microsoft Fabric and is refreshed for the first time. It is not uncommon to refresh large semantic models that the first refresh gets timeout and fails. There are a couple of possibilities causing the failure. Before we dig deeper, let’s take a moment to remind ourselves of what really happens behind the scenes on Microsoft Fabric when a semantic model containing a table with incremental refresh configuration refreshes for the first time. For your reference, this post explains everything in more detail.
What happens in Microsoft Fabric to semantic models containing tables with incremental refresh configuration? #
When we publish a semantic model from Power BI Desktop to Microsoft Fabric, each table in the published semantic model has a single partition. That partition contains all rows of the table that are also present in the data model on Power BI Desktop. When the first refresh operates, Microsoft Fabric creates data partitions, categorised as incremental and historical partitions, and optionally a real-time DirectQuery partition based on the incremental refresh policy configuration. When the real-time DirectQuery partition is configured, the table is a Hybrid table. I will discuss Hybrid tables in a future post.
Microsoft Fabric starts loading the data from the data source into the semantic model in parallel jobs. We can control the parallelism from the Power BI Desktop, from Options -> CURRENT FILE -> Data Load -> Parallel loading of tables. This configuration controls the number of tables or partitions that will be processed in parallel jobs. This configuration affects the parallelism of the current file on Power BI Desktop while loading the data into the local data model. It also influences the parallelism of the semantic model after publishing it to Microsoft Fabric.
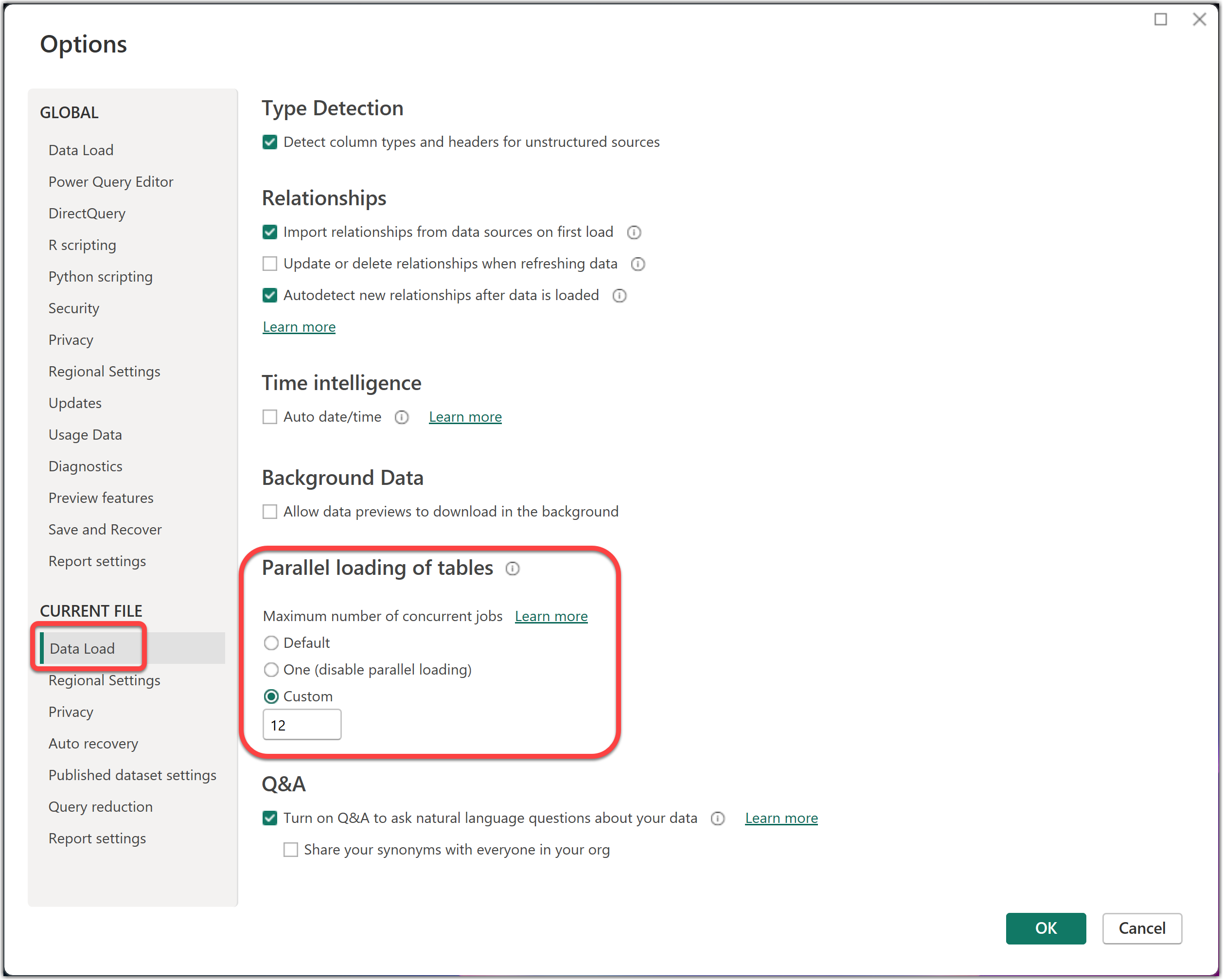
As the preceding image shows, I increased the Maximum number of concurrent jobs to 12.
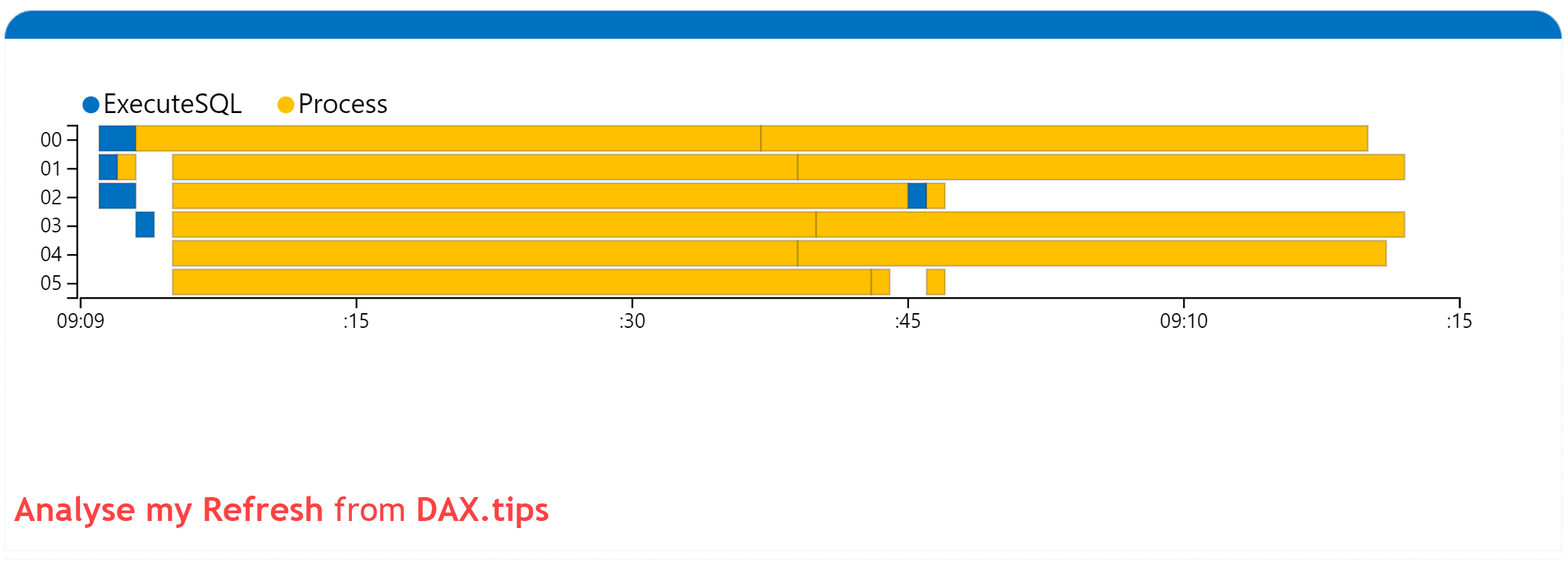
The following image shows refreshing the semantic model with 12 concurrent jobs on a Premium workspace on Microsoft:

The default is 6 concurrent jobs, meaning that when we refresh the model in Power BI Desktop or after publishing it to Microsoft Fabric, the refresh process picks 6 tables, or 6 partitions to run in parallel.
The following image shows refreshing the semantic model with the default concurrent jobs on a Premium workspace on Microsoft:
Tip
I used the Analyse my Refresh tool to visualise my semantic model refreshes. A big shout out to the legendary Phil Seamark for creating such an amazing tool. Read more about how to use the tool on Phil’s blog.
We can also change the Maximum number of concurrent jobs from third-party tools such as Tabular Editor; thanks to the amazing Daniel Otykier for creating this wonderful tool. Tabular Editor uses the SSAS Tabular model property called MaxParallelism which is shown as Max Parallelism Per Refresh on the tool (look at the below image from Tabular Editor 3).
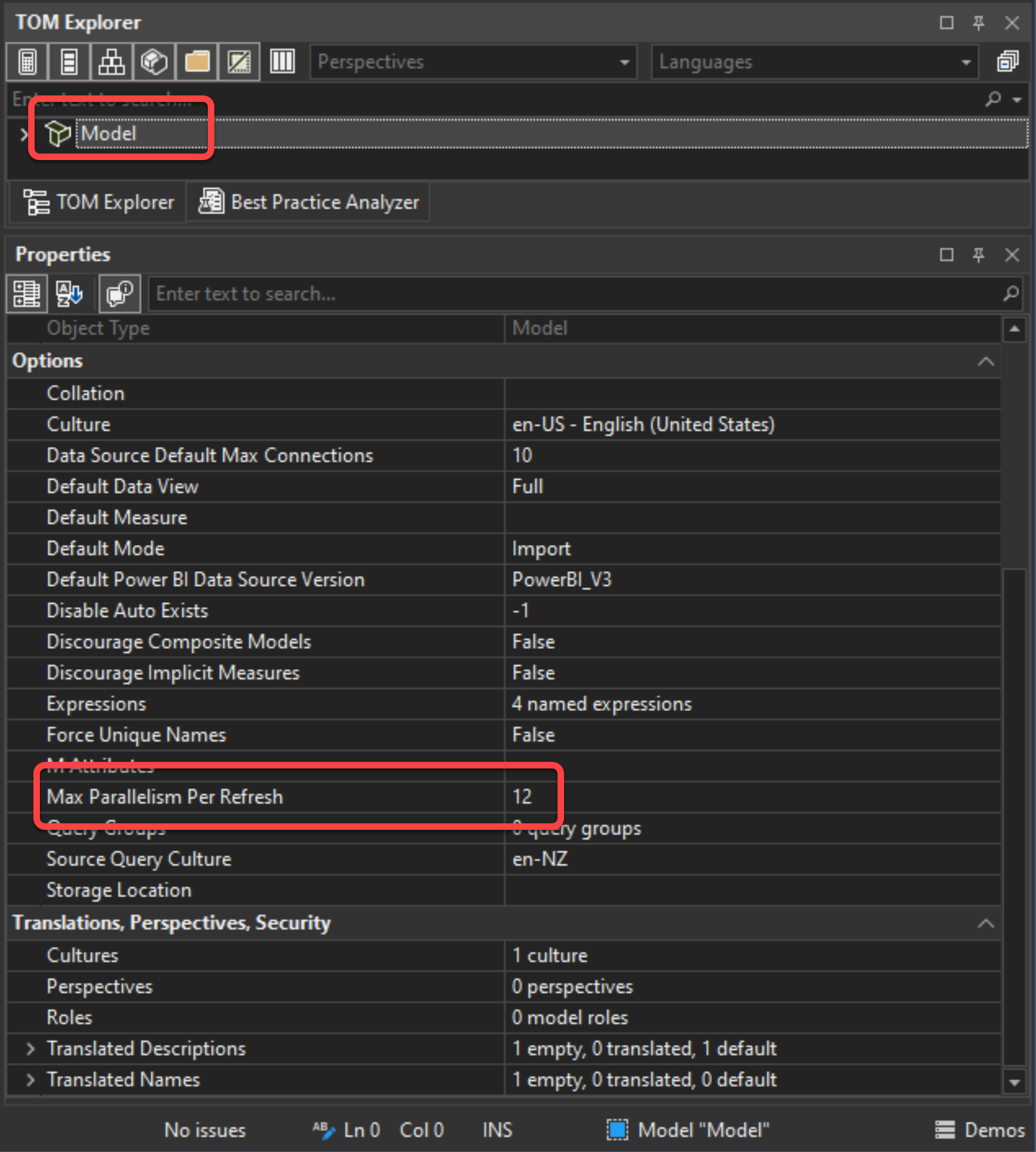
While loading the data in parallel might improve the performance, depending on the data volume being loaded into each partition, the concurrent query limitations on the data source, and the resource availability on your capacity, there is still a risk of getting timeouts. So as much as increasing the Maximum number of concurrent jobs is tempting, it is advised to change it with care. It is also worthwhile to mention that the behaviour of Power BI Desktop in refreshing the data is different from Microsoft Fabric’s semantic model data refresh activity. Therefore, while changing the Maximum number of concurrent jobs may influence the engine on Microsoft Fabric’s semantic model, it does not guarantee of getting better performance. I encourage you to read Chris Webb’s blog on this topic.
Practice 4: Consider applying incremental policies without partition refresh on premium semantic models #
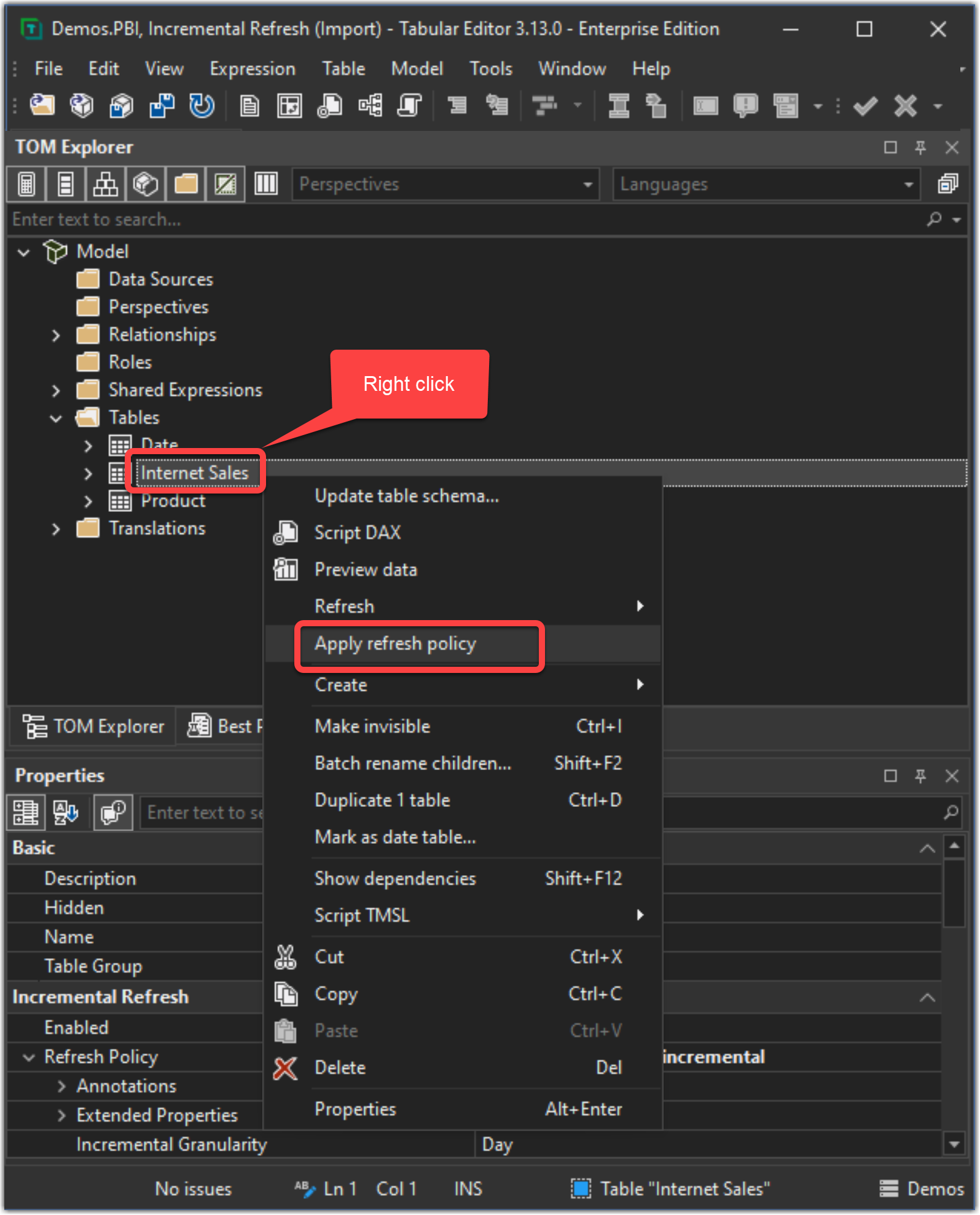
When working with large premium semantic models, implementing incremental refresh policies is a key strategy to manage and optimise data refreshes efficiently. However, there might be scenarios where we need to apply incremental refresh policies to our semantic model without immediately refreshing the data within the partitions. This practice is particularly useful to control the heavy lifting of the initial data refresh. By doing so, we ensure that our model is ready and aligned with our incremental refresh strategy, without triggering a time-consuming and resource-intensive data load.
There are a couple of ways to achieve this. The simplest way is to use Tabular Editor to apply the incremental policy meaning that all partitions are created but they are not processed. The following image shows the preceding process:
The other method that some developers might find beneficial, especially if you are not allowed to use third-party tools such as Tabular Editor is to add a new query parameter in the Power Query Editor on Power BI Desktop to control the data refreshes. This method guarantees that the first refresh of the semantic model after publishing it to Microsoft Fabric would be pretty fast without using any third-party tools. This means that Microsoft Fabric creates and refreshes (aka processes) the partitions, but since there is no data to load, the processing would be pretty quick.
The implementation of this technique is simple; we define a new query parameter. We then use this new parameter to filter out all data from the table containing incremental refresh. Of course, we want this filter to fold so the entire query on the Power Query side is fully foldable. So after we publish the semantic model to Microsoft Fabric, we apply the initial refresh. Since the new query parameter is accessible via the semantic model’s settings on Microsoft Fabric, we change its value after the initial data refresh to load the data when the next data refresh takes place.
It is important to note that changing the parameter’s value after the initial data refresh will not populate the historical Range. It means that when the next refresh happens, Microsoft Fabric assumes that the historical partitions are already refreshed and ignores them. Therefore, after the initial refresh the historical partitions remain empty, but the incremental partitions will be populated. To refresh the historical partitions we need to manually refresh them via XMLA endpoints which can be done using SSMS or Tabular Editor.
Explaining the implementation of this method makes this blog very long so I save it for a separate post. Stay tuned if you are interested in learning how to implement this technique.
Practice 5: Validate your partitioning strategy before implementation #
Partitioning strategy refers to planning how the data is going to be divided into partitions to match the business requirements. For example, let’s say we need to analyse the data for 10 years. As data volume to be loaded into a table is large, it doesn’t make sense to truncate the table and fully refresh it every night. During the discovery workshops, you found out that the data changes each day and it’s highly unlikely for the data to change up to 7 days.
In the preceding scenario, the historical range is 10 years and the incremental range is 7 days. As there are no indications of any real-time data change requirements, there is no need to keep the incremental range in DirectQuery mode which turns our table into a hybrid table.
The incremental policy for this scenario should look like the following image:
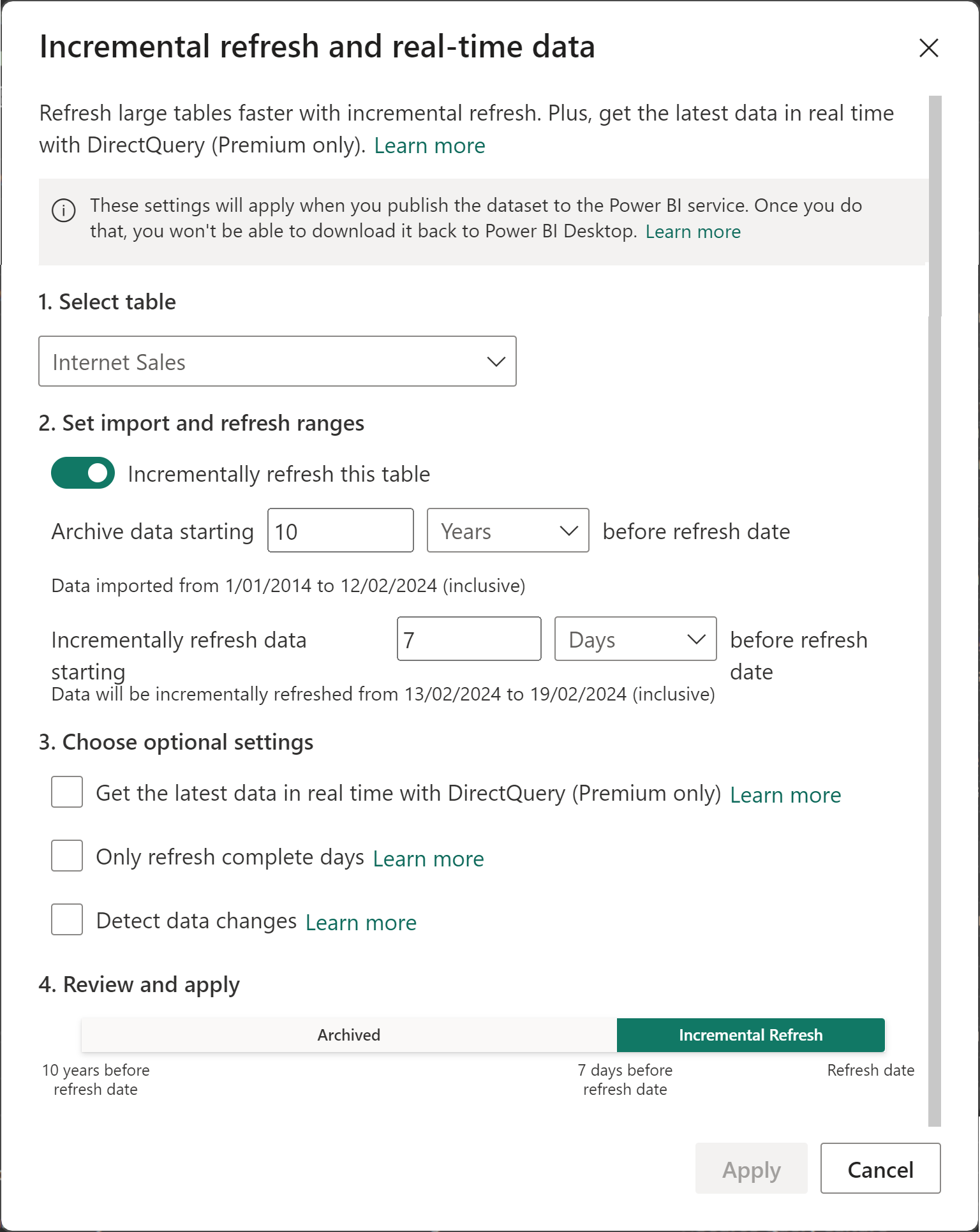
So after publishing the semantic model to Microsoft Fabric and the first refresh, the engine only refreshes the last 7 partitions on the next refreshes as shown in the following image:
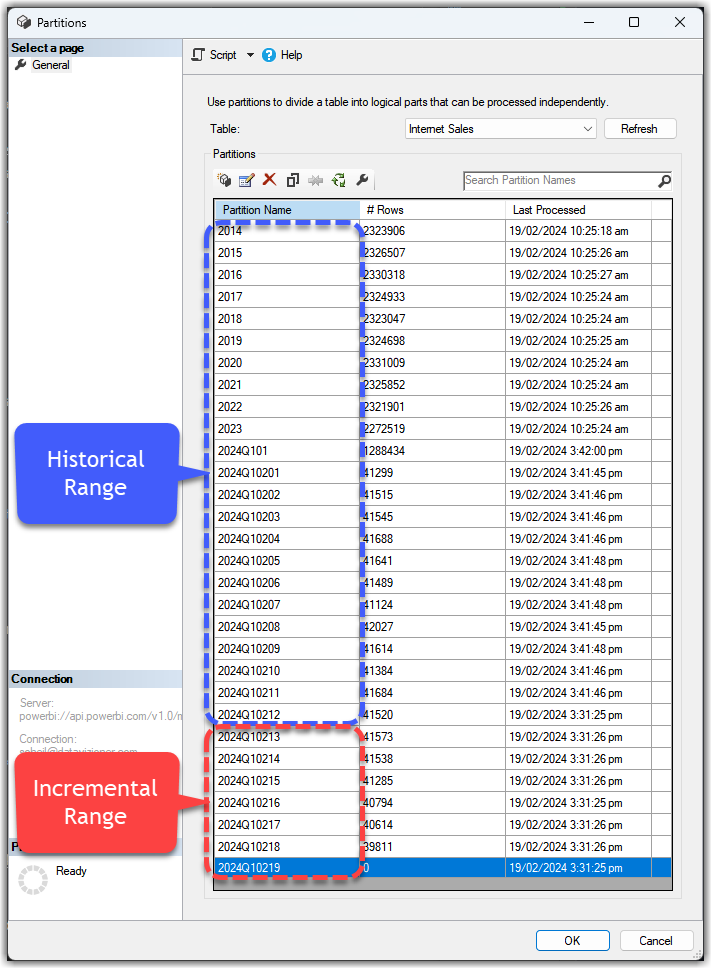
Deciding on the incremental policy is a strategic decision. An inaccurate understanding of the business requirements leads to an inaccurate partitioning strategy, hence inefficient incremental refresh which can have some serious side effects down the road. This is one of those cases that will lead to erasing the existing partitions, creating new partitions, and refreshing them for the first time. As you can see, a simple mistake in our partitioning strategy will lead to incorrect implementation that leads to a change in the partitioning policy which means a full data load will be required.
While understanding the business requirements during the discovery workshops is vital, we all know that the business requirements evolve from time to time; and honestly, the pace of the changes is sometimes pretty high.
For example, what happens if a new business requirement comes up involving real-time data processing for the incremental range aka hybrid table? While it might sound to be a simple change in the incremental refresh configuration, in reality, it is not that simple. To explain more, to get the best out of a hybrid table implementation, we should turn the storage mode of all the connected dimensions to the hybrid table into Dual mode. But that is not a simple process either if the existing dimensions’ storage modes are already set to Import. We cannot switch the storage mode of the tables from Import to either Dual or DirectQuery modes. This means that we have to remove and add these tables again which in real-world scenarios is not that simple. As mentioned before I will write another post about hybrid tables in the future, so you may consider subscribing to my blog to get notified on all new posts.
Practice 6: Consider using the Detect data changes for more efficient data refreshes #
Let’s explain this section using our previous example where we configured the incremental refresh to archive 10 years of data and incrementally refresh 7 days of data. This means Power BI is configured to only refresh a subset of the data, specifically the data from the last 7 days, rather than the entire semantic model. The default refreshing mechanism in Power BI for tables with incremental refresh configuration is to keep all the historical partitions intact, truncate the incremental partitions, and reload them. However in scenarios dealing with large semantic models, the incremental partitions could be fairly large, so the default truncation and load of the incremental partitions wouldn’t be an optimal approach. Here is where the Detect data changes feature can help. Configuring this feature in the incremental policy requires an extra DateTime column, such as LastUpdated, in the data source which is used by Power BI to first detect the data changes, then only refresh the specific partitions that have changed since the previous refresh instead of truncating and reloading all incremental partitions. Therefore, the refreshes potentially process smaller amounts of data utilising fewer resources compared to regular incremental refresh configuration. The column used for detecting data changes must be different from the one used to partition the data with the _RangeStart and RangeEnd parameters. Power BI uses the maximum value of the column used for defining the Detect data changes feature to identify the changes from the previous refresh and only refreshes the changed partitions and stores it in the refreshBookmark property of the partitions within the incremental range.
While the Detect data changes can improve the data refresh performance, we can enhance it even further. One possible enhancement would be to avoid importing the LastUpdated column into the semantic model which is likely to be a high-cardinality column. One option is to create a new query within the Power Query Editor in Power BI Desktop to identify the maximum date within the date range filtered by the RangeStart and RangeEnd parameters. We then use this query in the pollingExpression property of our refresh policy. This can be done in various ways such as running TMSL scripts via XMLA endpoint* or using Tabular Editor. I will also explain this method in more detail in a future post, so stay tuned.
Conclusion
This post of the Incremental Refresh in Power BI series delved into some best practices for implementing incremental refresh strategies, particularly for large semantic models, and underscored the importance of aligning these strategies with business requirements and data complexities. We’ve navigated through common challenges and offered practical best practices to mitigate risks, improve performance, and ensure smoother data refresh processes. I have a couple of more blogs from this series in my pipeline so stay tuned for those and subscribe to my blog to get notified when I publish a new post. I hope you enjoyed reading this long blog and find it helpful.
As always, feel free to leave your comments and ask questions, follow me on LinkedIn, YouTube and @_SoheilBakhshi on X (formerly Twitter).
Discover more from BI Insight
Subscribe to get the latest posts sent to your email.
How does incremental refresh work when records are removed from the source?
Hi Rui,
That’s a very good question. I will publish a post about how to manage data changes in the data source in near future. But in the meantime, I briefly answer your question.
Deleted data from the data sources is a change. Depending on your Incremental Refresh policies, the next refresh may or many capture those changes.
If the data change falls within the incremental range then it will be picked up in the next refresh. If it falls within the historical range, then the next refresh will not pick up the changes and your data will remain inaccurate unless you manually refresh the corresponding historical partition. To be able to do so, you need to have a premium license, either a PPU, a Power BI Premium Capacity or a Fabric Capacity as this is done via XMLA endpoints.
For more details, stay tuned for my next blogpost that exactly explains this scenario.
Cheers
Hi Soheil, thank you for the great blog. When will you be publishing the blog on refreshing the partitions in the historical range using power shell…as oppose to manually?
Hi Jamil.
Thanks for your comment. I have another blog in my list that must be published before this one which will happen this months.
Hi Soheil, thank you for the great blog. When will you be publishing the blog on refreshing the partitions in the historical range using power shell…as oppose to manually?